背景与说明
HAMi,是一个国产的GPU与国产加速卡(支持的GPU与国产加速卡型号与具体特性请查看此项目官网:
https://github.com/Project-HAMi/HAMi/
)虚拟化开源项目,实现以kubernetes为基础的容器场景下GPU或加速卡虚拟化。HAMi原名“k8s-vGPU-scheduler”,最初由第四范式公司开源,现已在国内与国际上愈加流行,是管理Kubernetes中异构设备的中间件。它可以管理不同类型的异构设备(如GPU、NPU等),在Pod之间共享异构设备,根据设备的拓扑信息和调度策略做出更好的调度决策。
为了阐述的简明性,本文只提供一种可行的办法,最终实现使用prometheus抓取监控指标并作为数据源、使用grafana来展示监控信息的目的。
本文假定已经部署好Kubernetes集群、HAMi。以下涉及到的相关组件都是在kubernetes集群内安装的,相关组件或软件版本信息如下:
组件或软件名称
版本
备注
kubernetes集群
v1.23.10
AMD64构架服务器环境下
HAMi
根据向开源作者提问,当前HAMi版本发行机制还不够成熟,暂以安装HAMi的scheduler.kubeScheduler.imageTag
参数值为其版本,此值要跟kubernetes版本看齐
项目地址:https://github.com/Project-HAMi/HAMi/
kube-prometheus stack
分支 release-0.11
dcgm-exporter
tag 3.2.5-3.1.7
部署与配置kube-prometheus
stack
部署kube-prometheus stack
注: kubernetes与kube-prometheus
stack的版本兼容矩阵请查看
https://github.com/prometheus-operator/kube-prometheus?tab=readme-ov-file#compatibility
,请根据自己的kubernetes版本选择合适版本的kube-prometheus stack
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 下载kube-prometheus代码仓库(此处使用分支 release-0.11) # 修改下grafana的service类型为NodePort。即在spec下添加type 配置项 # 类似的方法修改prometheus与alertmanager service类型为NodePort,它们的配置文件分别是manifests目录下的prometheus-service.yaml与alertmanager-service.yaml # 执行部署 # 创建的所有资源对象都在monitorin命名空间下,使用如下命令查看资源对象的运行状态
1 2 3 4 5 6 # 等monitorin命名空间下所有资源对象处于正常运行状态后,使用如下方式获取grafana、prometheus与alertmanager的svc信息
此时,假如控制节点的ip是10.0.0.21,则可以分别使用如下url访问grafana、prometheus与alertmanager:http://10.0.0.21:30300
、http://10.0.0.21:30090 、http://10.0.0.21:30093
,其中访问grafana的默认用户名与密码都是admin
笔者后来在部署好上述 kube-prometheus stack后,发现
自己笔记本电脑访问prometheus的nodeport-service+port时
提示连接超时,但在k8s集群内部访问控制节点+service/prometheus-k8s加port、service/prometheus-k8s的cluster-ip加port、pod/prometheus-k8s-xxx加3000端口都没有问题。此时可以检查
下networkpolicies,如果你知道修改networkpolicies规则请直接修改,否则可以直接删除相关networkpolicies,之后在自己笔记本电脑上访问grafana、prometheus与alertmanager相关界面就正常了。
image-20250110161557368
配置grafana
创建数据源ALL
访问”Configuration“->“Data
soutces”页面,创建一个名为"ALL"的数据源,其中HTTP.URL的值保持跟默认创建的数据源“prometheus”中的一样即可为
“http://prometheus-k8s.monitoring.svc:9090”
,然后保存上述数据源“ALL”
导入HAMi默认的dashboard
访问“Dashboards”->“Browse”页面,导入此dashboard:
https://grafana.com/grafana/dashboards/22043-hami-vgpu-metrics-dashboard/
,grafana中将创建一个名为“hami-vgpu-metrics-dashboard”的dashboard,此时此页面中有一些Panel如vGPUCorePercentage还没有数据,请继续看完此文档,执行完"部署dcgm-exporter"与“创建ServiceMonitor”中的步骤之后Panel数据将正常显示。
部署dcgm-exporter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 # 下载dcgm-exporter代码仓库(未看到与kubernetes的兼容矩阵说明,此处使用tag 3.2.5-3.1.7) # 修改 deployment/values.yaml 文件,为其中的serviceMonitor添加relabelings配置,这样dcgm-exporter的监控指标才有node_name与ip属性 # 只有这一处serviceMonitor,relabelings内的内容都是添加的,添加后内容如下 # 使用helm工具在monitoring空间下安装dcgm-exporter # 查看helm install结果 # 还需确认dcgm-exporter 相关的pod已经处于running状态
创建ServiceMonitor
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 # 创建文件hami-device-plugin-svc-monitor.yaml # 文件hami-device-plugin-svc-monitor.yaml内容如下 # 应用此文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 # 创建文件hami-scheduler-svc-monitor.yaml # 文件hami-scheduler-svc-monitor.yaml内容如下 # 应用此文件
1 2 3 4 5 # 确认创建的ServiceMonitor
确认最终监控效果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 创建文件gpu-pod.yaml,尝试使用HAMi虚拟出来的NVIDIA vGPU # 应用此文件
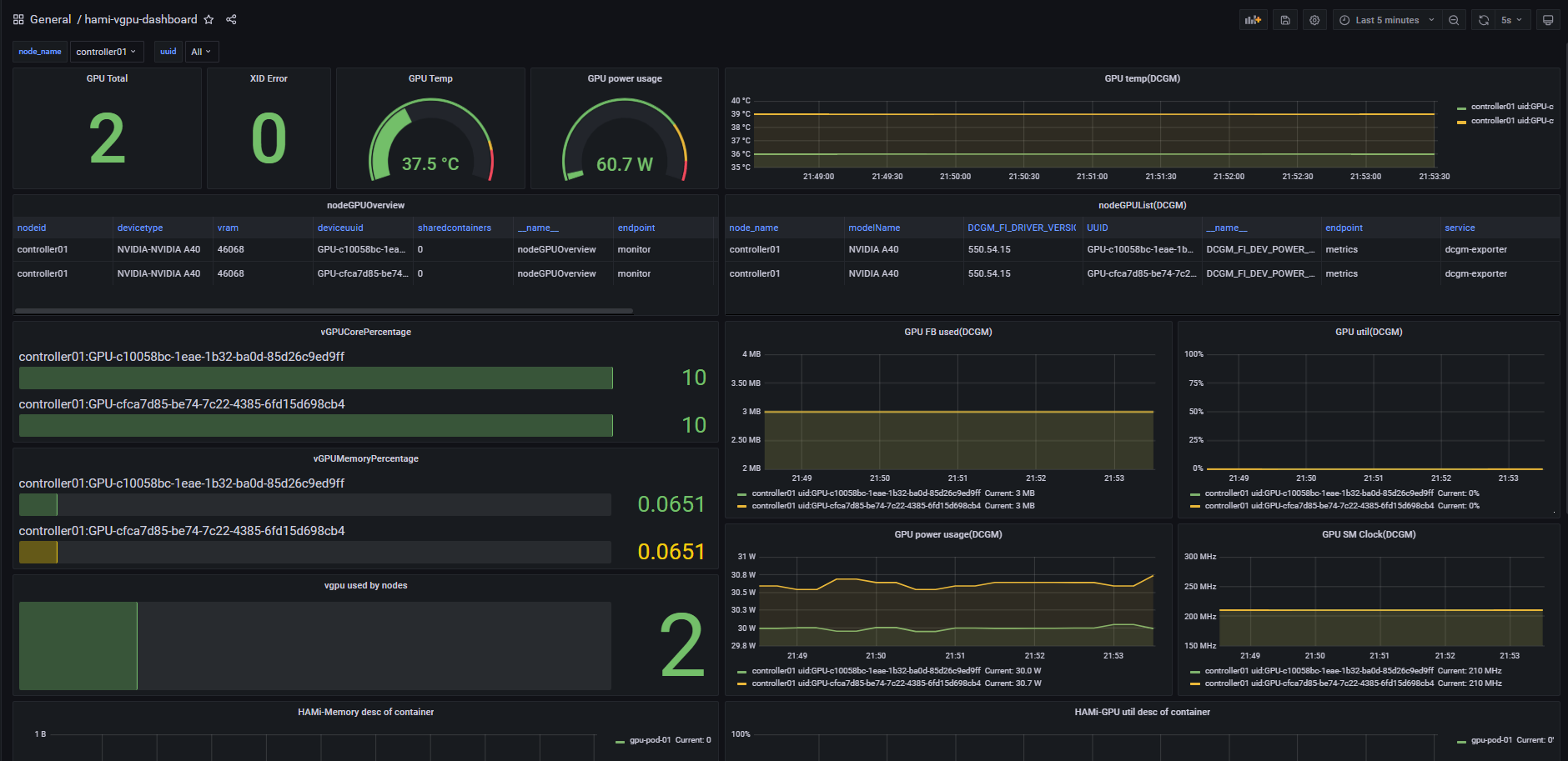
此时,应该可以dashboard中看到监控详情。
导入dashboard时少许panel如“GPU
Total”的内容可能未被正确解析,将造成其内容不能正常显示,此时请将dashboard文件下载下来,手动编辑对应内容,将数据源“Data
source”修改为"ALL",同时将“Metrics
browser”修改正确的promQL语句(可以从下载下来的dashboard中查找),其他默认即可。如果不会修改,这里也提供一份在grafana8.5.5中可用的dashboard,阿里云盘分享链接https://www.alipan.com/s/1X8fTqisx6y
提取码: r48s
正常时,内容大概如下
image-20241003215400685