一、介绍
概述
HAMi,英文全称是“Heterogeneous AI Computing Virtualization
Middleware”,是一个GPU与加速卡(支持的GPU与国产加速卡型号与具体特性请查看此项目官网:
https://github.com/Project-HAMi/HAMi/
)虚拟化国产开源项目,实现了以kubernetes为基础的容器场景下GPU或加速卡虚拟化。此项目最初由第四范式公司开源,原名“k8s-vGPU-scheduler”,后改名为HAMi(中文名为哈蜜),经过两三年的发展,现已在国内与国际上愈加流行,成为小型或科研机构提供容器场景下GPU或加速卡设备虚拟化的解决方案雏形或基础。它提供了管理多种不同类型的异构设备(目前支持NVIDIA
GPU、寒武纪MLU、天数智芯GPU、中科署光DCU、华为昇腾NPU、摩尔线程GPU)的能力,能够在Pod之间共享异构设备,根据设备的拓扑信息和调度策略做出更好的调度决策。
考虑到当前国内人工智能、高性能计算、机器学习等需要大量计算任务的工作负载对NVIDIA
GPU及其他国产加速卡如海光DCU、昇腾NPU、寒武纪MLU等的使用特点。第一,其中一个显著的特点就是一个加速卡最多只能分配给一个任务,这个加速卡的资源如计算核心与显存并未被充分复用,其中很大一部分内存可能被浪费掉了,HAMi这一开源项目能够解决这一问题。第二,HAMi使得能够在同一个k8s环境中同时支持对多个不同品牌的加速设备(异构加速设备)的虚拟共享,这就是HAMi名称中异构的来源。(笔者目前的理解,其他功能如“动态MIG切片”还有待进一起深入研究学习中)。
能力与特性
HAMi 提供了针对包括NVIDIA
GPU在内的等异构设备的虚拟化能力,能力主要包括两个方面即设备复用与资源隔离。
设备复用:
允许通过指定显存来申请虚拟算力设备
允许通过指定算力使用比例来申请虚拟算力设备
资源隔离:
HAMi
调度器提供了管理GPU集群的能力,具体包括如下功能特性(不同GPU或加速卡支持的功能特性可能会稍有差别,我只用过少数几种,此处未能完整归纳总结。以前官网提供了功能特性支持矩阵,最近删除了):
GPU 共享 可限制分配的显存大小 可限制分配的计算核心数 虚拟显存 指定GPU型号 无侵入
构架设计
HAMi项目官网是:https://github.com/Project-HAMi/HAMi/tree/master
,目前(2025年1月初)稳定版本是v2.4.1 。
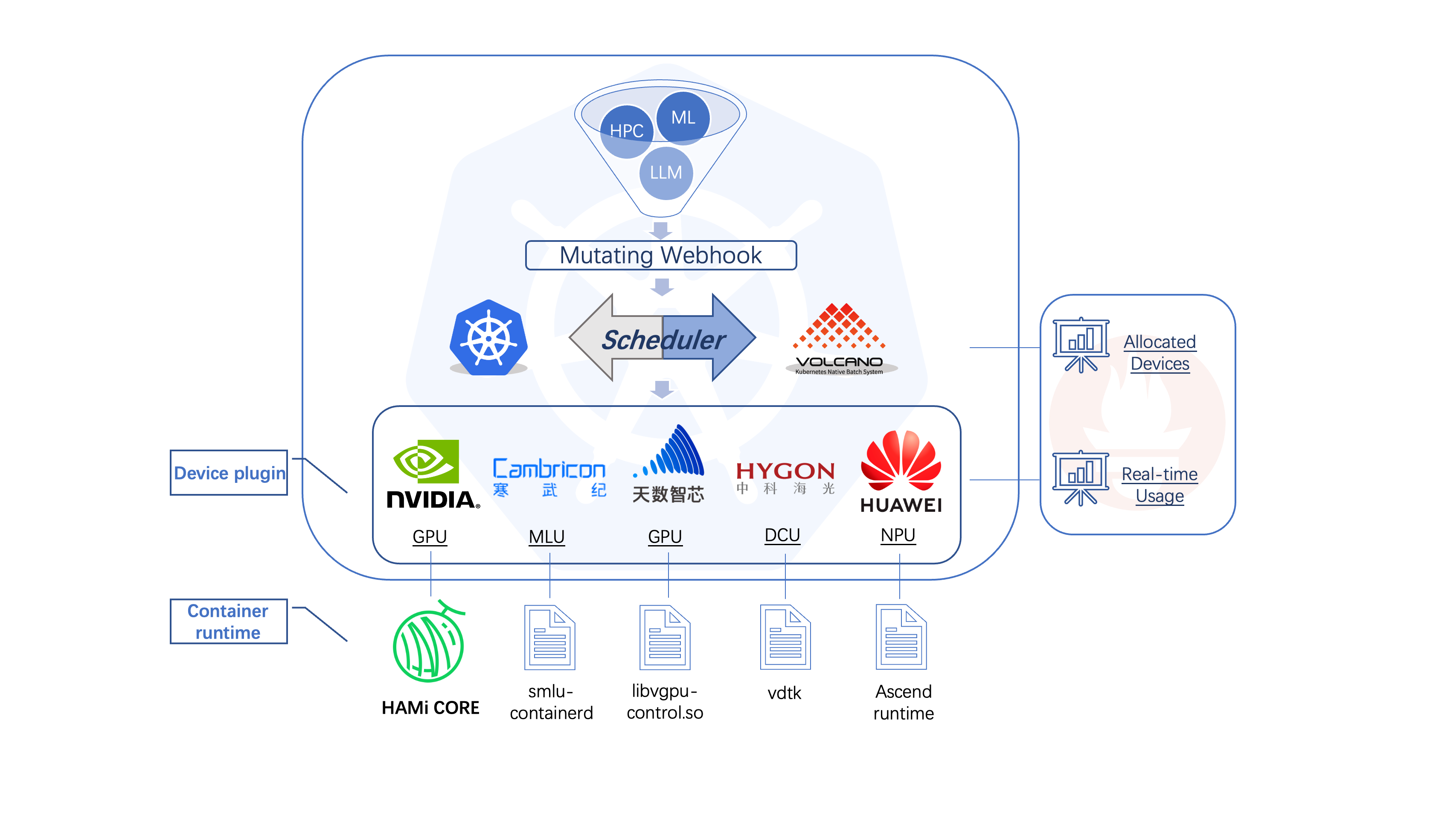
HAMi
包含以下几个组件,一个统一的mutatingwebhook,一个统一的调度器,以及针对各种不同的异构算力设备对应的设备插件和容器内的控制组件,整体的架构特性如下图所示。
hami-arch.png
二、部署升级与卸载
安装要求
NVIDIA drivers >= 440
nvidia-docker version > 2.0
docker/containerd/cri-o,已配置nvidia作为默认runtime
Kubernetes version >= 1.16
glibc >= 2.17 & glibc < 2.3.0
kernel version >= 3.10
helm > 3.0
安装
以下以安装与使用HAMi2.4.0为例进行说明。
执行安装
1 2 3 4 5 6 7 8 9 10 11 12 13 # 查看k8s版本 # 首先需要将所有要使用到的GPU节点打上gpu=on标签,没有此标签的k8s节点会被HAMi忽略 # 在 helm 中添加hami chart仓库 # 使用以下命令进行部署#并客制化参数,resourceName是申请vgpu个数的资源名,默认值是"nvidia.com/gpu" ,它跟NVIDIA device pulgin安装后生成的资源名一样,为了区别二者,此处将其客制化为"nvidia.com/vgpu" # 参数“--version 2.4.0“是指定此次安装的 HAMi 版本,如果不指定的话,默认安装最新版本2.4.1 # 安装耗时可能要几分钟,安装完成时输出如下
image-20250104180859741
上述“helm install”命令可以客制化的参数较多,比如:
devicePlugin.deviceSplitCount:
整数类型,预设值是10。GPU的分割数,每一张GPU都不能分配超过其配置数目的任务。若其配置为N的话,每个GPU上最多可以同时存在N个任务
resourceMemPercentage:
字符串类型,申请vgpu显存比例资源名,默认:
"nvidia.com/gpumem-percentage"
其他可客制化参数
可以直接参考官方文档:https://github.com/Project-HAMi/HAMi/blob/v2.4.0/docs/config_cn.md
确认安装情况
1 2 # 1.查看已发布版本
image-20250104180953889
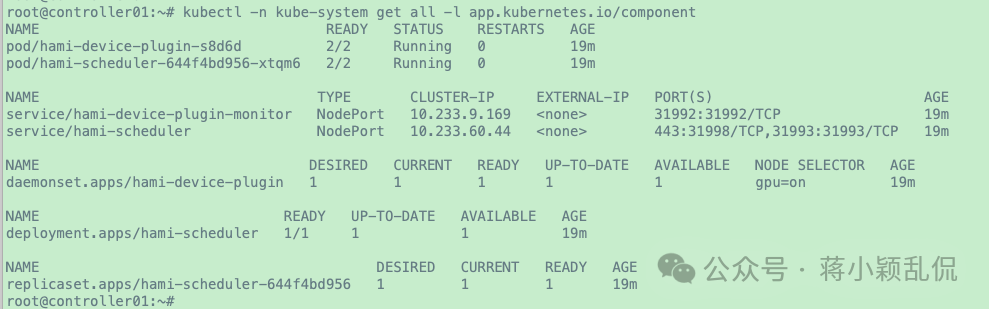
1 2 3 4 5 6 7 8 # 2.查看k8s集群内资源对象,正常情况类似如下 # 每个被打了标签“gpu=on”的k8s节点上都会有一个名为hami-device-plugin-xxx的pod; # 同时会有一个名为hami-scheduler-xxx 的pod # 会有hami-device-plugin-monitor、hami-scheduler两个service # 会有一个名为hami-device-plugin的daemonset # 会有一个名为hami-scheduler的deployment # 会有一个名为hami-scheduler-yyy的replicaset
image-20250104181215738
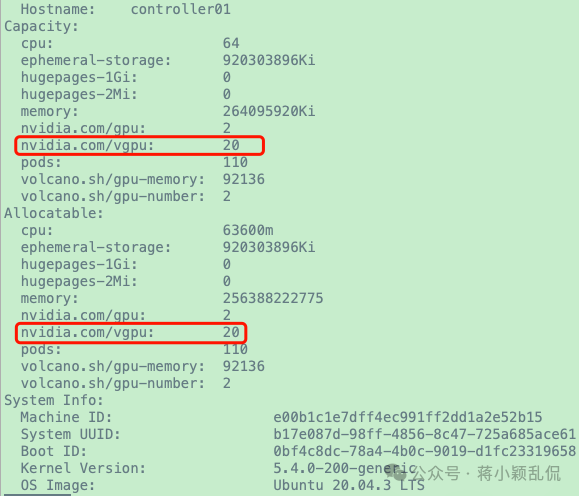
1 2 # 3.查看k8s节点拥有的属性
image-20250104181300572
升级
1 2 3 # 比如先前安装了HAMi2.4.0版本,现在想升级到HAMi2.4.1版本 # 执行升级HAMi版本
image-20250104181337643
1 2 # 查看升级后的HAMi版本
image-20250104181359099
卸载
1 2 # 在任意目录直接执行如下命令即可
三、简单使用
简单用法讲解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 root@controller01:~# vi gpu-test3.yaml
1 2 3 4 5 6 7 8 9 # 可以在上述yaml文件的 metadata 中添加annotations,实现对异构资源的自定义使用 annotations: # metadata: # annotations: # nvidia.com/nouse-gputype: "A40" # nvidia.com/use-gputype: "A40" # nvidia.com/nouse-gpuuuid: "GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4" # nvidia.com/use-gpuuuid: "GPU-2e240d3e-69be-8cec-3ffc-d9da5cc7b8c3" # hami.io/node-scheduler-policy: "spread" # hami.io/gpu-scheduler-policy: "binpack"
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 # 应用上述文件 # 可以看到pod/gpu-test3-01的宿主机是controller01,上面有一个GPU进程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 进入pod的容器内部查看,可以看到有两个vGPU,它们的显存都只有23034MiB。虽然申请了两个vGPU,但其实只有0号vGPU被使用了,它的GPU使用率是15%,临时功率是113W
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 # 查看pod日志
更多官方示例
参考:https://github.com/Project-HAMi/HAMi/tree/v2.4.0/examples
四、问题或faq
参考官网issues:https://github.com/Project-HAMi/HAMi/issues
五、资源监控
可以参考笔者归纳总结的这篇文章:
https://jiangsanyin.github.io/2024/10/07/GPU%E8%99%9A%E6%8B%9F%E5%8C%96%E5%BC%80%E6%BA%90%E9%A1%B9%E7%9B%AEHAMi%E4%B8%AD%E4%BD%BF%E7%94%A8prometheus%E4%B8%8Egrafana%E5%81%9A%E7%9B%91%E6%8E%A7/
,
建议直接看官方文档。此监控相关文档由笔者自己编写,已经提交给HAMi官方项目仓库、当前被HAMi官方项目仓库接受并合入主线分支中。
六、更新与参考
后续如有修正或完善,将继续更新。可能后续会发表HAMi系列学习记录。
七、参考资源
HAMi代码仓库:https://github.com/Project-HAMi/HAMi
项目官网:https://project-hami.io/
官方公众号:“HAMi Project”
KubeSphere B站官方账号发表的一个以HAMi为主题的推讲视频,在2024-12-31
下午发布