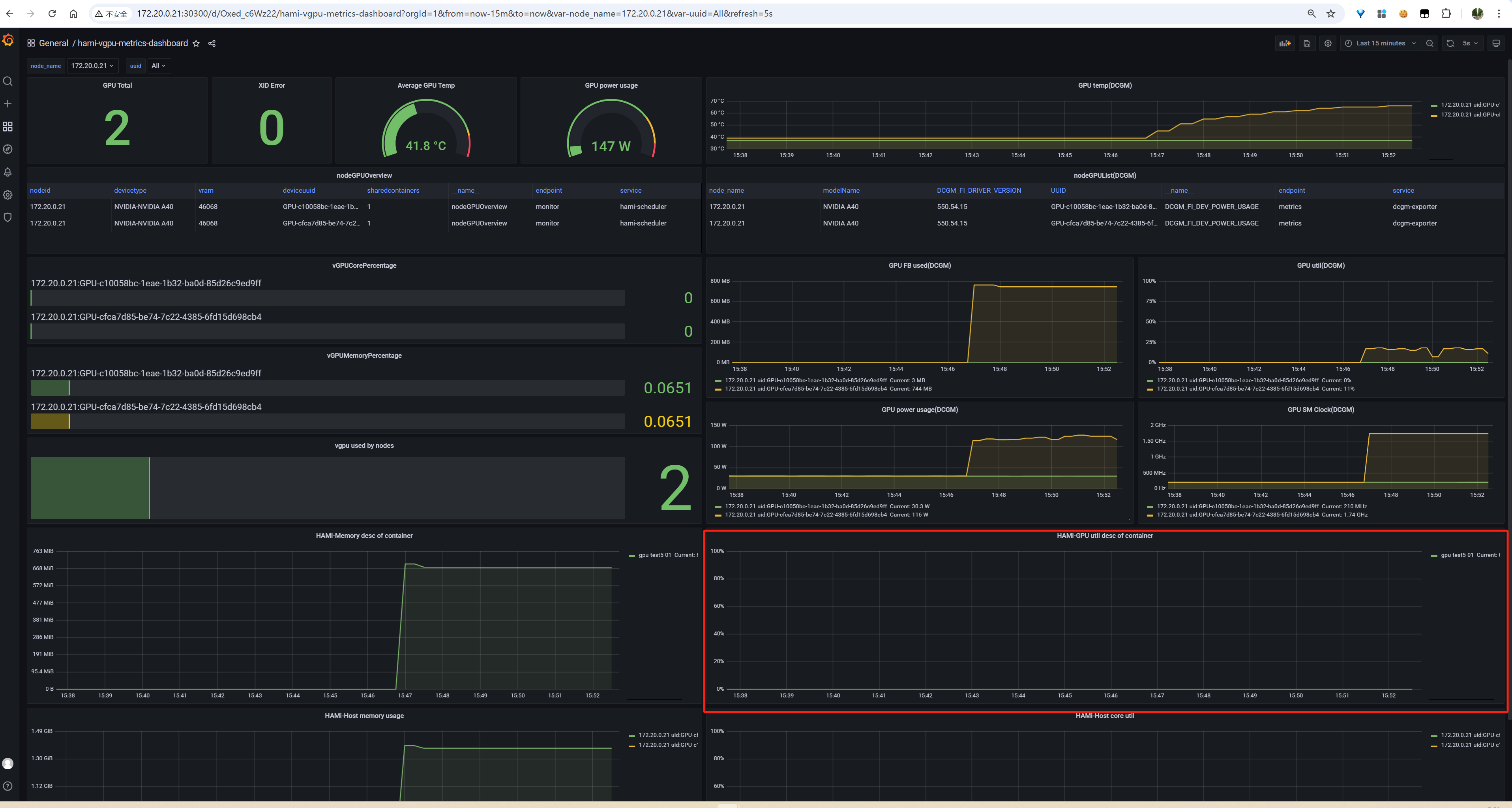
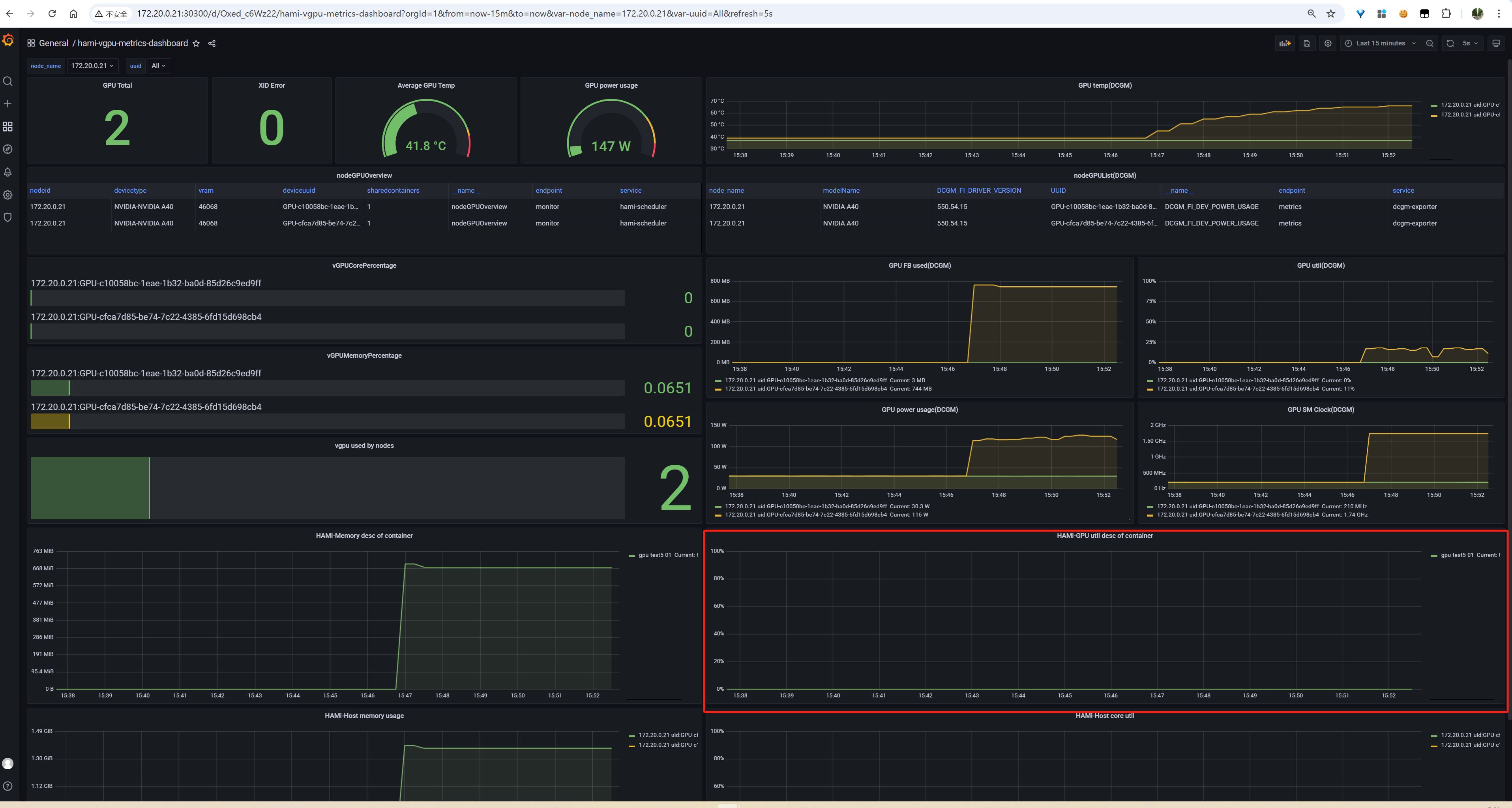
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| #从上面可以看到svc/dcgm-exporter 的类型是ClusterIP,它的工作端口是9400
root@controller01:/opt/installPkgs/k8s-vgpu-basedon-HAMi# curl 10.68.32.112:9400/metrics
# HELP DCGM_FI_DEV_SM_CLOCK SM clock frequency (in MHz).
# TYPE DCGM_FI_DEV_SM_CLOCK gauge
DCGM_FI_DEV_SM_CLOCK{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 1740
DCGM_FI_DEV_SM_CLOCK{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 210
# HELP DCGM_FI_DEV_MEM_CLOCK Memory clock frequency (in MHz).
# TYPE DCGM_FI_DEV_MEM_CLOCK gauge
DCGM_FI_DEV_MEM_CLOCK{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 7250
DCGM_FI_DEV_MEM_CLOCK{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 405
# HELP DCGM_FI_DEV_GPU_TEMP GPU temperature (in C).
# TYPE DCGM_FI_DEV_GPU_TEMP gauge
DCGM_FI_DEV_GPU_TEMP{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 66
DCGM_FI_DEV_GPU_TEMP{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 37
# HELP DCGM_FI_DEV_POWER_USAGE Power draw (in W).
# TYPE DCGM_FI_DEV_POWER_USAGE gauge
DCGM_FI_DEV_POWER_USAGE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 124.967000
DCGM_FI_DEV_POWER_USAGE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 30.280000
# HELP DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION Total energy consumption since boot (in mJ).
# TYPE DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION counter
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 7187773583
DCGM_FI_DEV_TOTAL_ENERGY_CONSUMPTION{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 7015882815
# HELP DCGM_FI_DEV_PCIE_REPLAY_COUNTER Total number of PCIe retries.
# TYPE DCGM_FI_DEV_PCIE_REPLAY_COUNTER counter
DCGM_FI_DEV_PCIE_REPLAY_COUNTER{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_PCIE_REPLAY_COUNTER{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_GPU_UTIL GPU utilization (in %).
# TYPE DCGM_FI_DEV_GPU_UTIL gauge
DCGM_FI_DEV_GPU_UTIL{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 16
DCGM_FI_DEV_GPU_UTIL{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_MEM_COPY_UTIL Memory utilization (in %).
# TYPE DCGM_FI_DEV_MEM_COPY_UTIL gauge
DCGM_FI_DEV_MEM_COPY_UTIL{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 8
DCGM_FI_DEV_MEM_COPY_UTIL{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_ENC_UTIL Encoder utilization (in %).
# TYPE DCGM_FI_DEV_ENC_UTIL gauge
DCGM_FI_DEV_ENC_UTIL{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_ENC_UTIL{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_DEC_UTIL Decoder utilization (in %).
# TYPE DCGM_FI_DEV_DEC_UTIL gauge
DCGM_FI_DEV_DEC_UTIL{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_DEC_UTIL{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_XID_ERRORS Value of the last XID error encountered.
# TYPE DCGM_FI_DEV_XID_ERRORS gauge
DCGM_FI_DEV_XID_ERRORS{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_XID_ERRORS{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_FB_FREE Framebuffer memory free (in MiB).
# TYPE DCGM_FI_DEV_FB_FREE gauge
DCGM_FI_DEV_FB_FREE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 44718
DCGM_FI_DEV_FB_FREE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 45400
# HELP DCGM_FI_DEV_FB_USED Framebuffer memory used (in MiB).
# TYPE DCGM_FI_DEV_FB_USED gauge
DCGM_FI_DEV_FB_USED{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 684
DCGM_FI_DEV_FB_USED{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 3
# HELP DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL Total number of NVLink bandwidth counters for all lanes.
# TYPE DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL counter
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_VGPU_LICENSE_STATUS vGPU License status
# TYPE DCGM_FI_DEV_VGPU_LICENSE_STATUS gauge
DCGM_FI_DEV_VGPU_LICENSE_STATUS{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_VGPU_LICENSE_STATUS{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS Number of remapped rows for uncorrectable errors
# TYPE DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS counter
DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_UNCORRECTABLE_REMAPPED_ROWS{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS Number of remapped rows for correctable errors
# TYPE DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS counter
DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_CORRECTABLE_REMAPPED_ROWS{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_DEV_ROW_REMAP_FAILURE Whether remapping of rows has failed
# TYPE DCGM_FI_DEV_ROW_REMAP_FAILURE gauge
DCGM_FI_DEV_ROW_REMAP_FAILURE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
DCGM_FI_DEV_ROW_REMAP_FAILURE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0
# HELP DCGM_FI_PROF_GR_ENGINE_ACTIVE Ratio of time the graphics engine is active (in %).
# TYPE DCGM_FI_PROF_GR_ENGINE_ACTIVE gauge
DCGM_FI_PROF_GR_ENGINE_ACTIVE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.160959
DCGM_FI_PROF_GR_ENGINE_ACTIVE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.000000
# HELP DCGM_FI_PROF_PIPE_TENSOR_ACTIVE Ratio of cycles the tensor (HMMA) pipe is active (in %).
# TYPE DCGM_FI_PROF_PIPE_TENSOR_ACTIVE gauge
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.010100
DCGM_FI_PROF_PIPE_TENSOR_ACTIVE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.000000
# HELP DCGM_FI_PROF_DRAM_ACTIVE Ratio of cycles the device memory interface is active sending or receiving data (in %).
# TYPE DCGM_FI_PROF_DRAM_ACTIVE gauge
DCGM_FI_PROF_DRAM_ACTIVE{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.061415
DCGM_FI_PROF_DRAM_ACTIVE{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 0.000325
# HELP DCGM_FI_PROF_PCIE_TX_BYTES The rate of data transmitted over the PCIe bus - including both protocol headers and data payloads - in bytes per second.
# TYPE DCGM_FI_PROF_PCIE_TX_BYTES gauge
DCGM_FI_PROF_PCIE_TX_BYTES{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 6811221
DCGM_FI_PROF_PCIE_TX_BYTES{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 1837182
# HELP DCGM_FI_PROF_PCIE_RX_BYTES The rate of data received over the PCIe bus - including both protocol headers and data payloads - in bytes per second.
# TYPE DCGM_FI_PROF_PCIE_RX_BYTES gauge
DCGM_FI_PROF_PCIE_RX_BYTES{gpu="0",UUID="GPU-cfca7d85-be74-7c22-4385-6fd15d698cb4",device="nvidia0",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 40172789
DCGM_FI_PROF_PCIE_RX_BYTES{gpu="1",UUID="GPU-c10058bc-1eae-1b32-ba0d-85d26c9ed9ff",device="nvidia1",modelName="NVIDIA A40",Hostname="172.20.0.21",DCGM_FI_DRIVER_VERSION="550.54.15",container="",namespace="",pod=""} 1166047
root@controller01:/opt/installPkgs/k8s-vgpu-basedon-HAMi#
|