一、写在前面
本文章总结了在Docker环境使用“NVIDIA
GPU”,它的效率与直接在物理服务器启动进程使用物理服务器上的NVIDIA
GPU效率差不多,所以是一种高效与常用的NVIDIA
GPU云原生场景下的使用方式。能够在Docker环境使用“NVIDIA
GPU”后,只需要在Docker环境所在的服务器上再部署 Kubernetes
环境、安装nvidia-device-plugin 后即可以在 Kubernetes 环境使用NVIDIA
GPU。
本文中涉及的Docker环境宿主机的操作系统有两种:Ubuntu20-amd64、Centos7.9-amd64。
其他说明
- 本文假设服务器安装有NVIDIA GPU,且操作系统上已经安装NVIDIA驱动
- 本文假设服务器的操作系统上已经安装好 Docker 服务
- 本文不对其中原理细节(如nvidia-docker2/nvidia-container-toolkit的工作原理)进行阐述,此部分内容过多,将单独整理成文
二、Ubuntu20/22/24-amd64
此章节在Ubuntu20-amd64中验证成功。Ubuntu22/24-amd64操作系统上,安装配置Docker环境及相关配置步骤应该跟Ubuntu20-amd64中一样(个人猜测,还没验证)
2.1 设置 repository 和 GPG key
1
2
3
| distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
|
2.2 安装 nvidia-docker2
参考文档:Installing
the NVIDIA Container Toolkit、nvidia-container-toolkit的github仓库
1
2
3
4
| #nvidia-docker2 软件包包括一个自定义的 daemon.json 文件,用于将 NVIDIA 运行时注册为 Docker 的默认运行时,以及一个向后兼容 NVIDIA -Docker 1.0 的脚本。
#如果安装了 NVIDIA -docker 1.0 ,则需要在安装 NVIDIA 运行时之前删除它和任何现有的 GPU 容器。
apt-get update
apt-get install -y nvidia-docker2
|
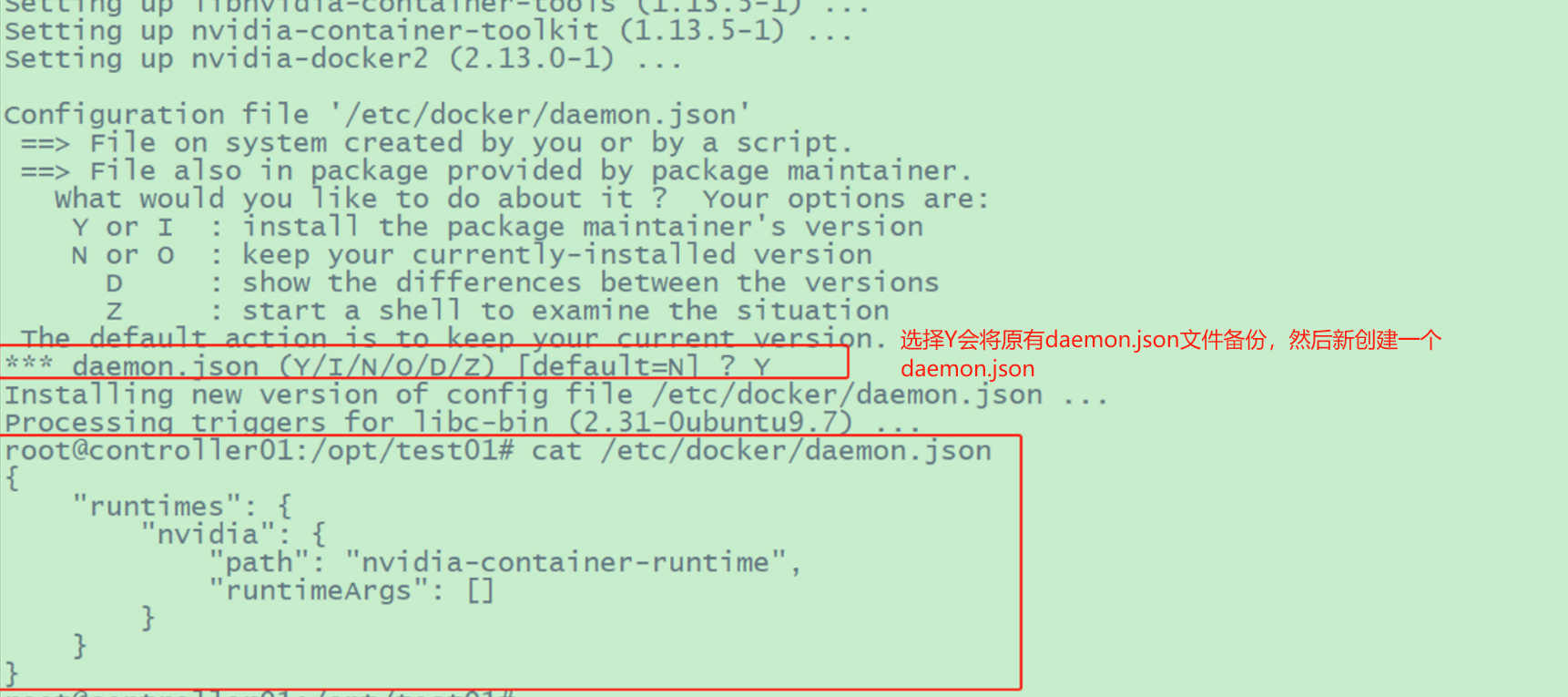 image-20250124161020395
image-20250124161020395
2.3 配置 Docker 守护进程文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #
#增加如下内容
root@controller01:~# cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
#其他的自定义配置
}
#最终得到的daemon.json文件内容可能如下:
root@controller01:~# cat /etc/docker/daemon.json
{
"default-runtime": "nvidia",
"runtimes": {
"nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
},
#其他的自定义配置
"exec-opts": ["native.cgroupdriver=systemd"],
"dns": [
"223.5.5.5",
"223.6.6.6",
"202.103.0.68",
"8.8.8.8"
],
"insecure-registries": [
"172.20.0.21:4000", #自己的harbor仓库
"172.24.0.31:443"
],
"log-opts": {
"max-file": "5",
"max-size": "50m"
},
"registry-mirrors": [
"https://registry.aliyuncs.com",
"https://registry.docker-cn.com",
"https://docker.chenby.cn",
"https://docker.registry.cyou",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://dockerproxy.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
]
}
|
2.4 重启docker进程
1
2
3
| #重启docker进程
systemctl daemon-reload
systemctl restart docker
|
2.5
至此已可在Docker容器中使用NVIDIA GPU
1
2
3
4
5
6
7
8
9
10
11
12
| #使用一张卡:--gpus='"device=0"';使用第0,1张卡:--gpus='"device=0,1"';使用全部GPU:--gpus all
#通过序号指定GPU(此时不要加“--privileged”参数,否则仍然可以看到所有GPU)
docker run -idt \
--name ubuntu2204 \
--gpus='"device=0,1"' \
ubuntu:22.04
#指定所有GPU
docker run -idt \
--name ubuntu2204 \
--gpus all \
ubuntu:22.04
|
2.6 安装nvidia-device-plugin
此步骤及后续步骤需要先安装好K8S环境,且要求K8S环境使用高级容器运行时是Docker。
部署使用高级容器运行时是Docker的K8S环境文档,可参见前面发布的博客文章
1
2
3
4
5
| #下载并应用nvidia-device-plugin(最新的文件见https://github.com/NVIDIA/k8s-device-plugin)
wget https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.1/nvidia-device-plugin.yml
#应用此yaml文件
kubectl create -f nvidia-device-plugin.yml
|
1
2
3
4
5
| #安装成功后,可以在kube-system空间下看到一个运行正常的 ds/nvidia-device-plugin-daemonset (笔者k8s环境只有一个节点,此节点上有NVIDIA GPU)
root@controller01:~# kubectl -n kube-system get daemonsets.apps
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
...
nvidia-device-plugin-daemonset 1 1 1 1 1 <none> 2m20s
|
2.7 验证k8s中GPU是否可用
1
2
| #1 验证NVIDIA GPU是否已经注册到k8s节点
kubectl describe node controller01 #假设controller01上面有NVIDIA GPU
|
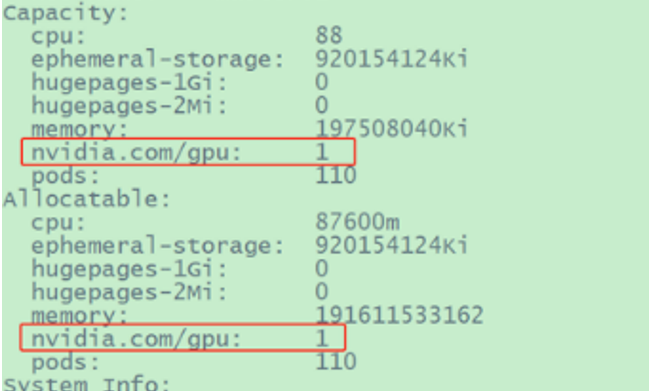 image-20250124163002248
image-20250124163002248
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #2 验证k8s中能否正常使用NVIDIA GPU
#创建一个pod以试用GPU,此pod定义文件如下
root@controller01:~# touch RunningGPUJobs.yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
restartPolicy: Never
containers:
- name: cuda-container
image: nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda10.2
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
tolerations:
- key: nvidia.com/gpu
operator: Exists
effect: NoSchedule
root@controller01:~# kubectl apply -f RunningGPUJobs.yaml
#上述命令将在默认命名空间下创建一个pod/gpu-pod,它处于Running状态后,其中程序很快就会运行完成从面pod变成Completed状态
#查看pod/gpu-pod的日志
root@controller01:~# kubectl logs gpu-pod
|
 image-20250124163229713
image-20250124163229713
三、Centos7.9-amd64
3.1 配置Repository
1
2
3
| distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.repo | tee /etc/yum.repos.d/nvidia-container-runtime.repo
|
3.2 安装 nvidia-docker2
1
2
| yum makecache -y
yum install nvidia-docker2 -y
|
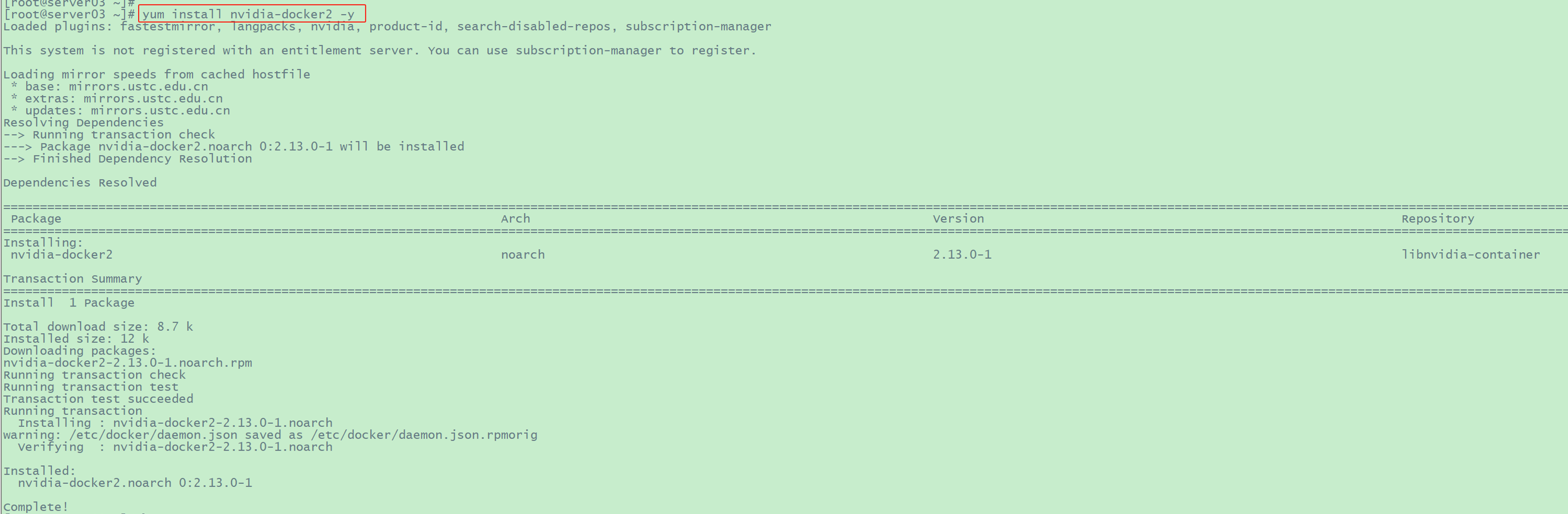 image-20250124163714236
image-20250124163714236
后续步骤跟“Ubuntu20/22/24-amd64”上时一样
四、几个容器镜像同步网站
docker proxy:docker proxy
public-image-mirror:public-image-mirror
渡渡鸟镜像同步站:https://docker.aityp.com/