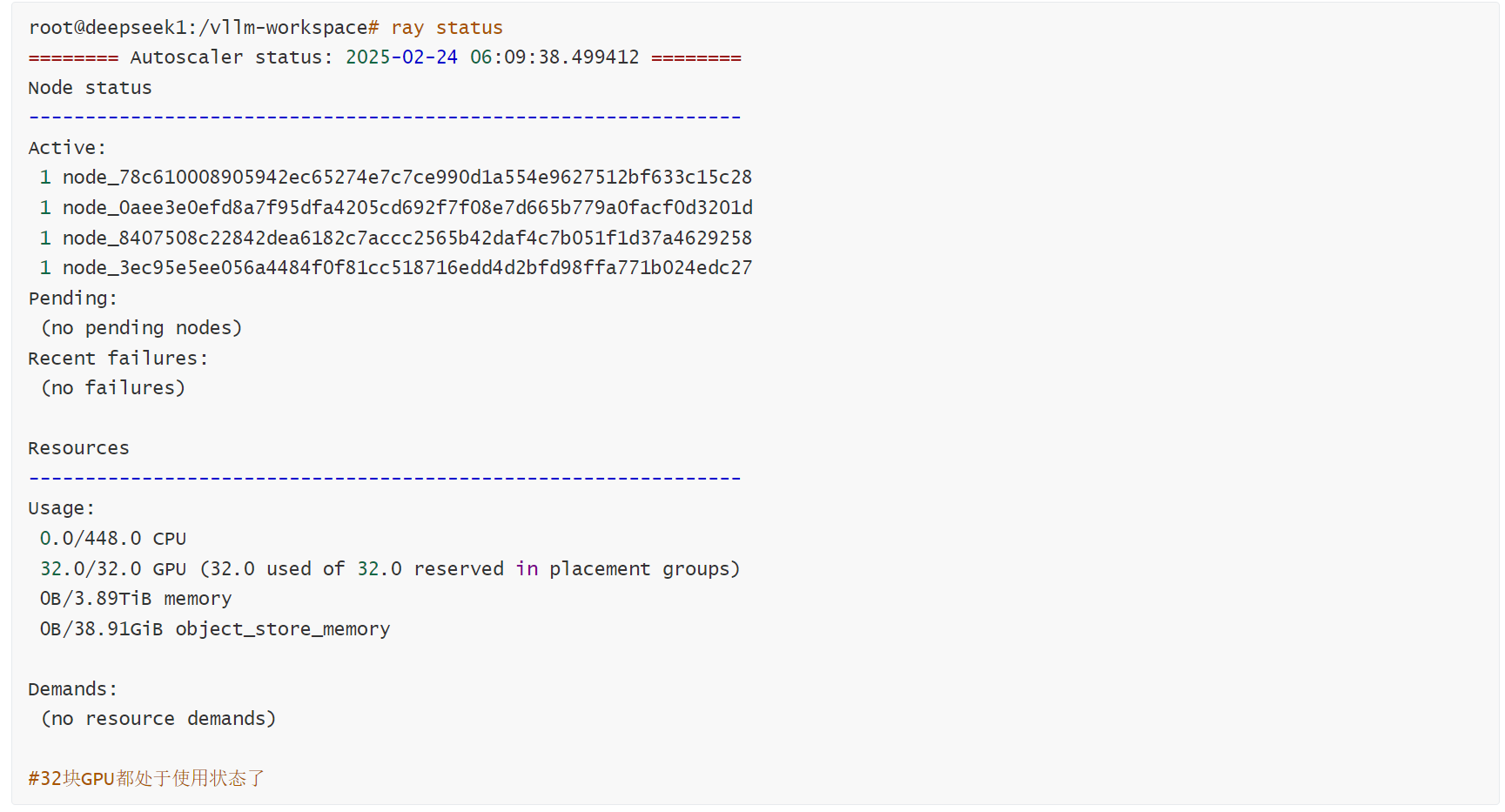
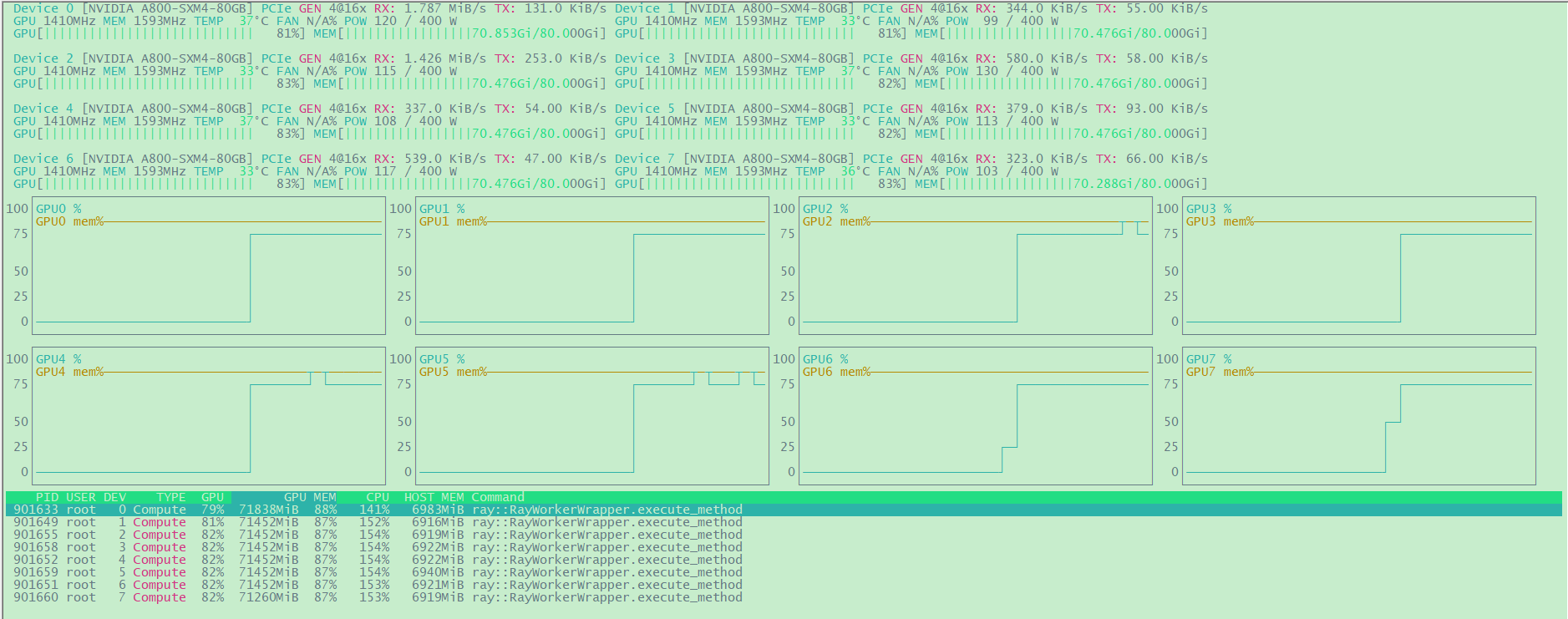
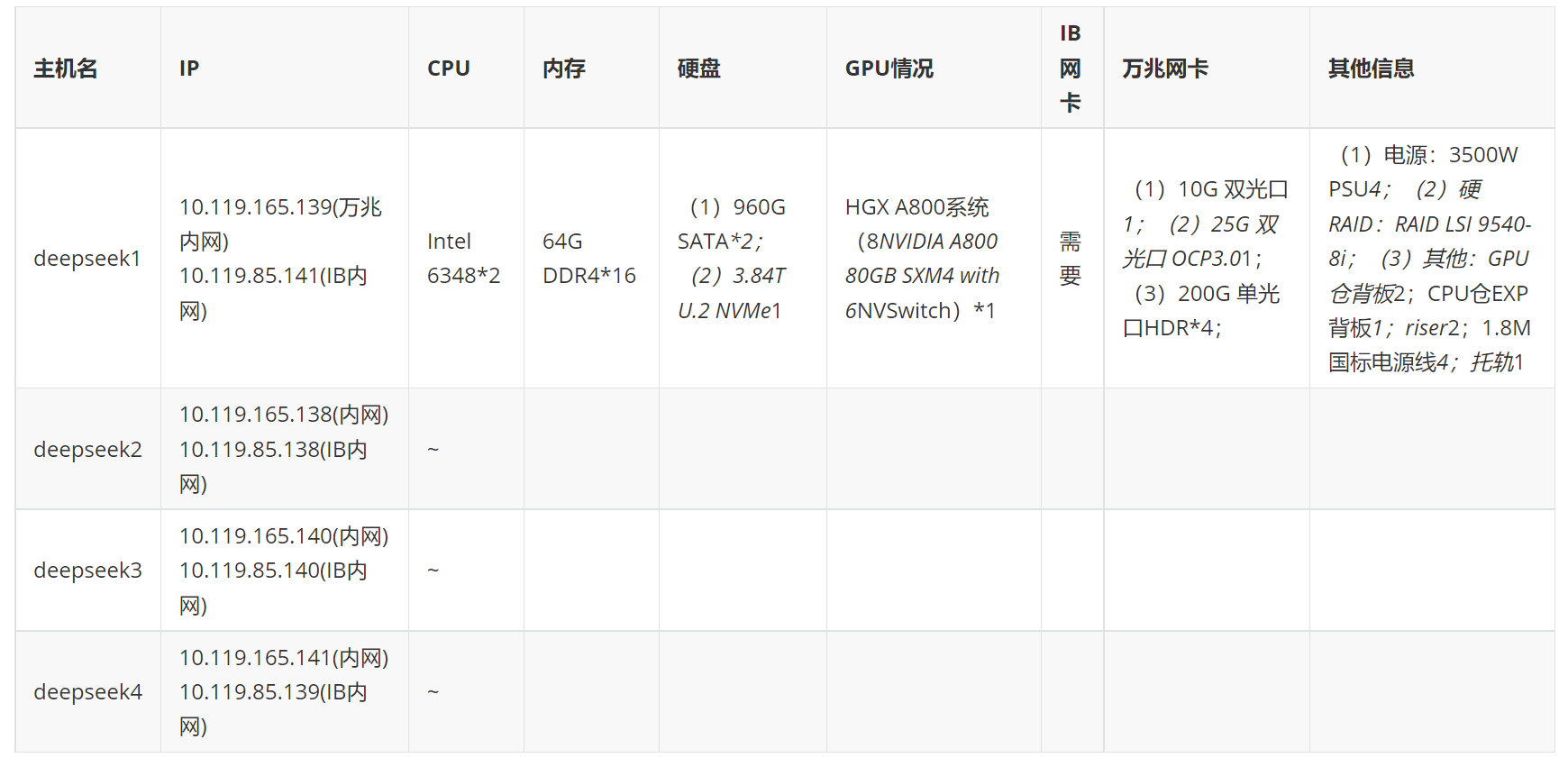
1
2
3
4
5
6
7
8
9
10
| #回答问题的同时在vllm serve命令执行的窗口会看到如下,显示token平均生成吞吐率
INFO 02-24 17:21:12 metrics.py:455] Avg prompt throughput: 1.6 tokens/s, Avg generation throughput: 36.5 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 02-24 17:21:17 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 37.2 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 02-24 17:21:22 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 36.5 tokens/s, Running: 1 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.1%, CPU KV cache usage: 0.0%.
...
#甚至更高速度
INFO 02-24 23:32:00 metrics.py:455] Avg prompt throughput: 442.9 tokens/s, Avg generation throughput: 38.8 tokens/s, Running: 3 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.4%, CPU KV cache usage: 0.0%.
INFO 02-24 23:32:05 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 102.4 tokens/s, Running: 3 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.4%, CPU KV cache usage: 0.0%.
INFO 02-24 23:32:07 async_llm_engine.py:179] Finished request chatcmpl-03add50cba264c84afe98fd6cce9907f.
INFO 02-24 23:32:10 metrics.py:455] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 79.4 tokens/s, Running: 2 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.3%, CPU KV cache usage: 0.0%.
|