PyTorch框架基础实践
一、PyTorch简介
1.1 PyTorch是什么
Ø 开源的机器学习/深度学习框架( https://pytorch.org/ )
Ø 2017年1月,FAIR(Facebook AI Research)发布了PyTorch 0.1
Ø 它强调易用性和灵活性,并允许用深度学习领域惯用的 Python 来表示深度学习模型
Ø PyTorch 提供了一个核心数据结构—张量(Tensor)
Ø 类似的框架还有TensorFlow、PaddlePaddle、MindSpore等
1.2 环境搭建
1 | |
1 | |
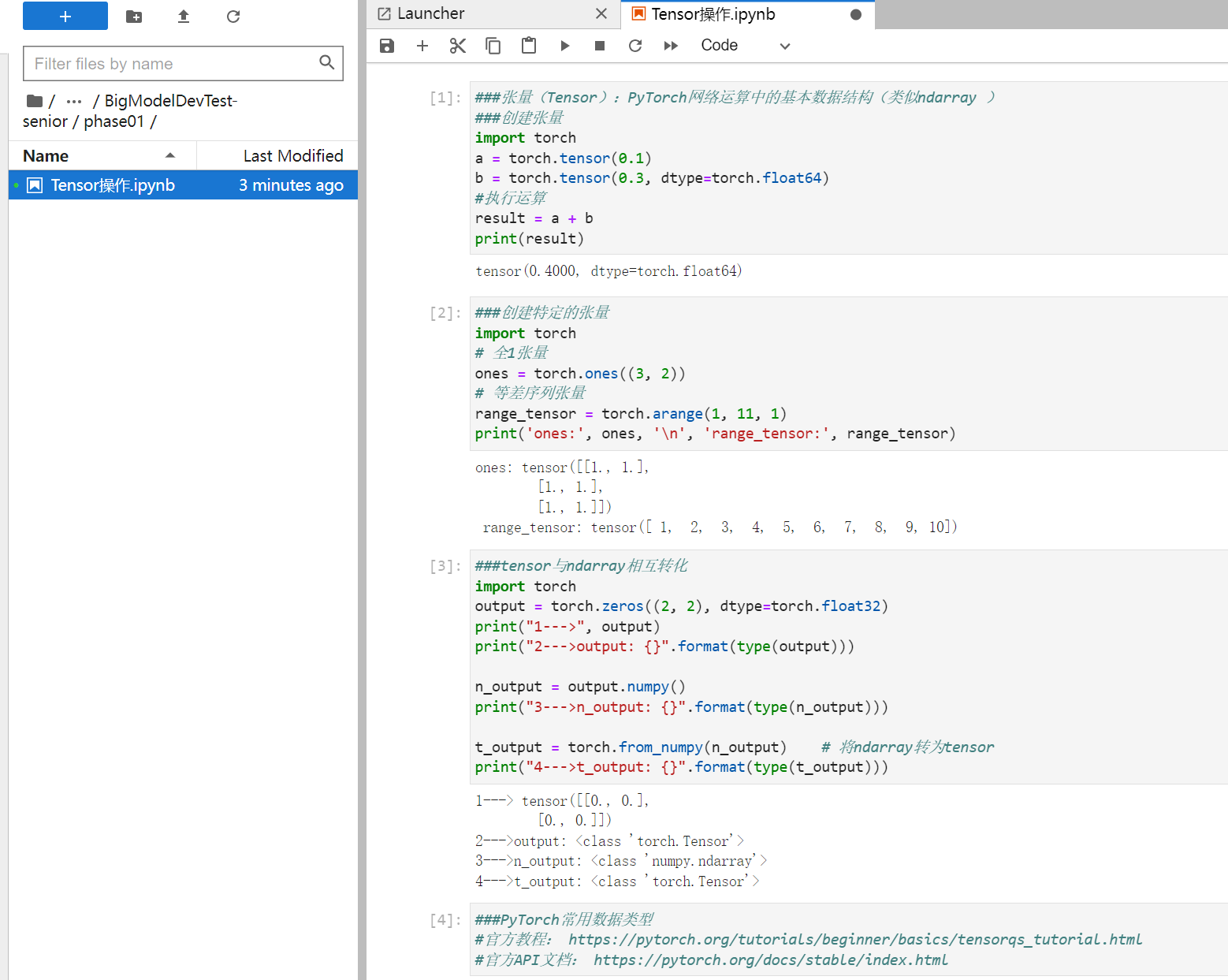
二、Tensor操作
张量(Tensor):PyTorch网络运算中的基本数据结构(类似ndarray )
1 | |
1 | |
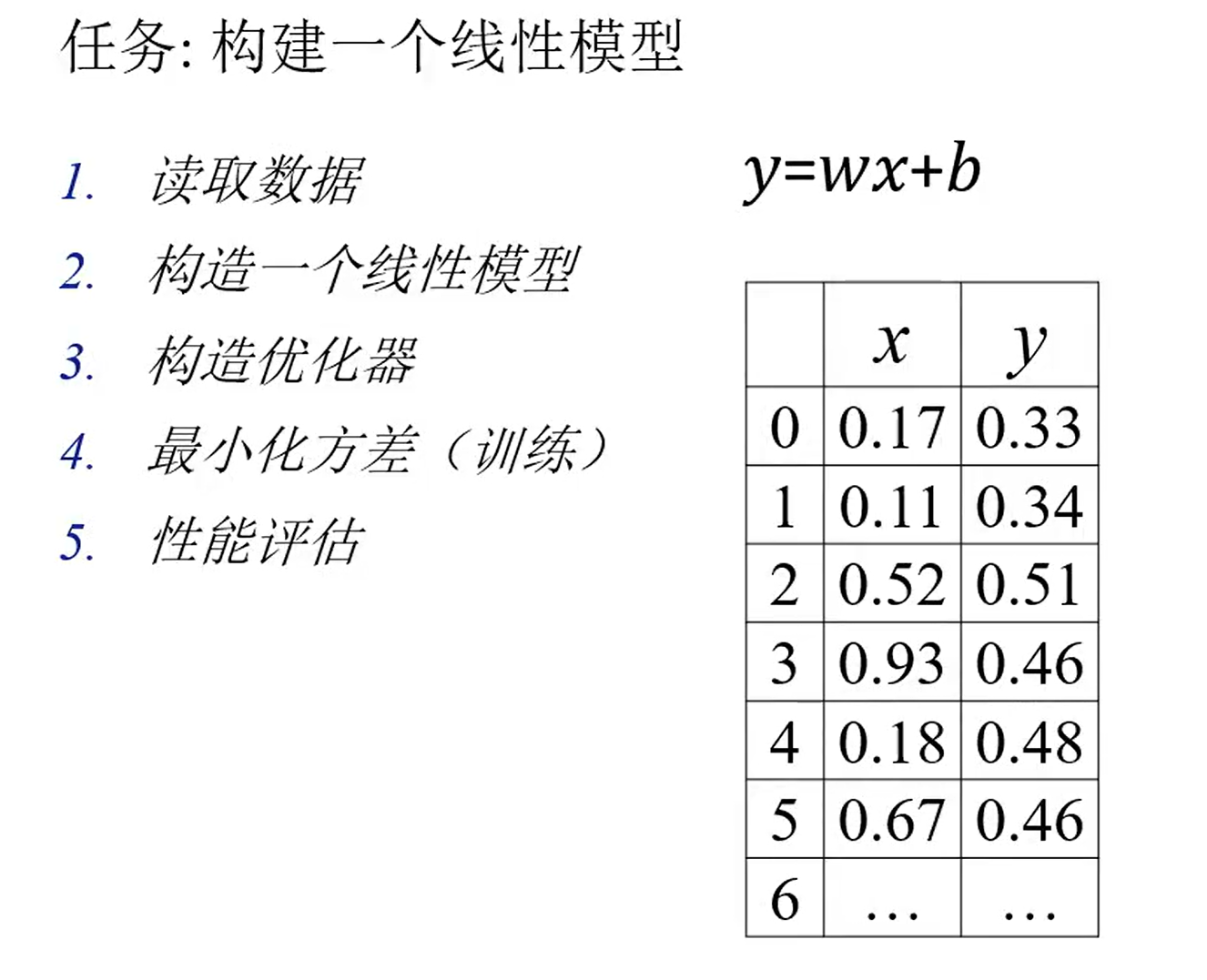
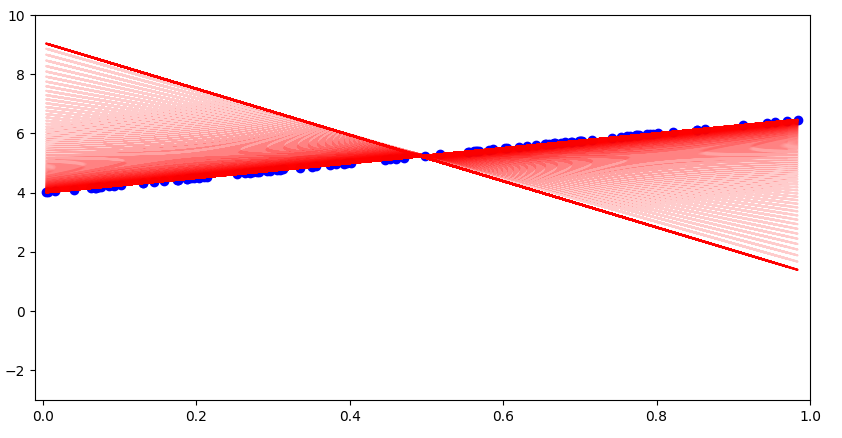
三、构建一个线性模型
任务描述

1 | |
四、识别手写数字
案例流程
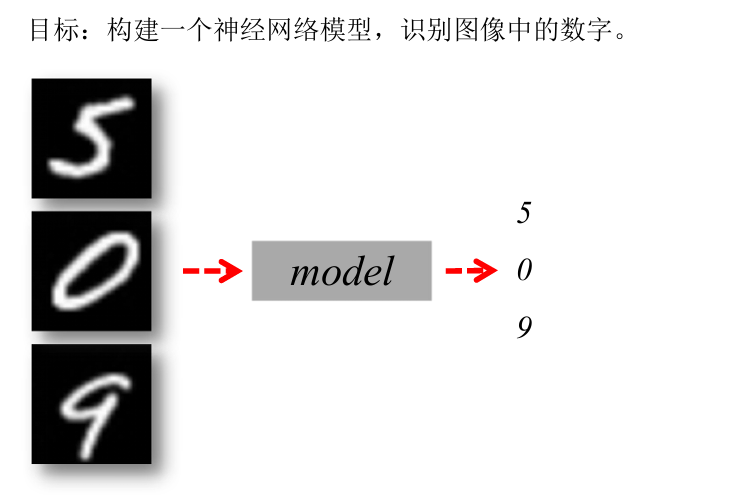


各个步骤与代码片段




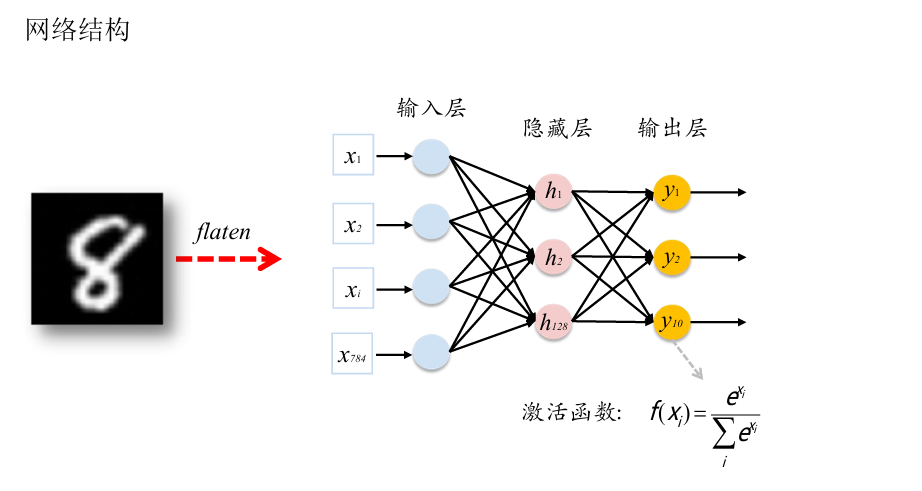
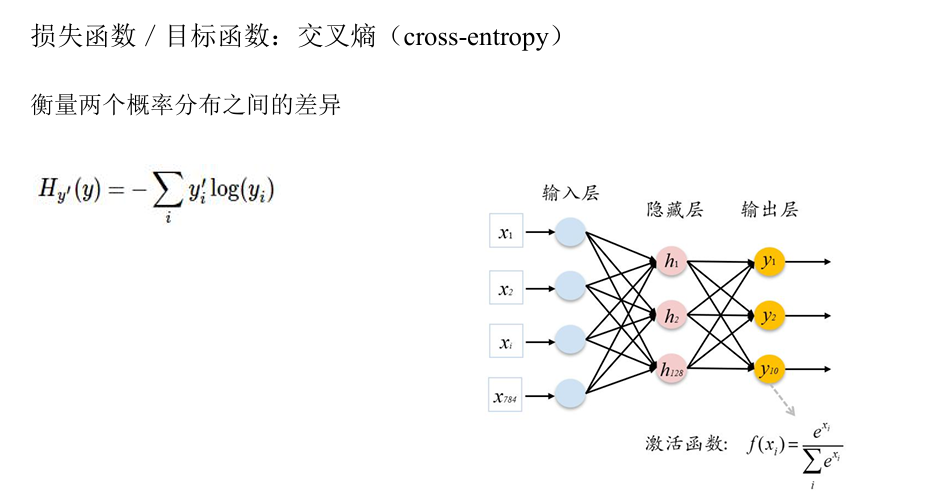
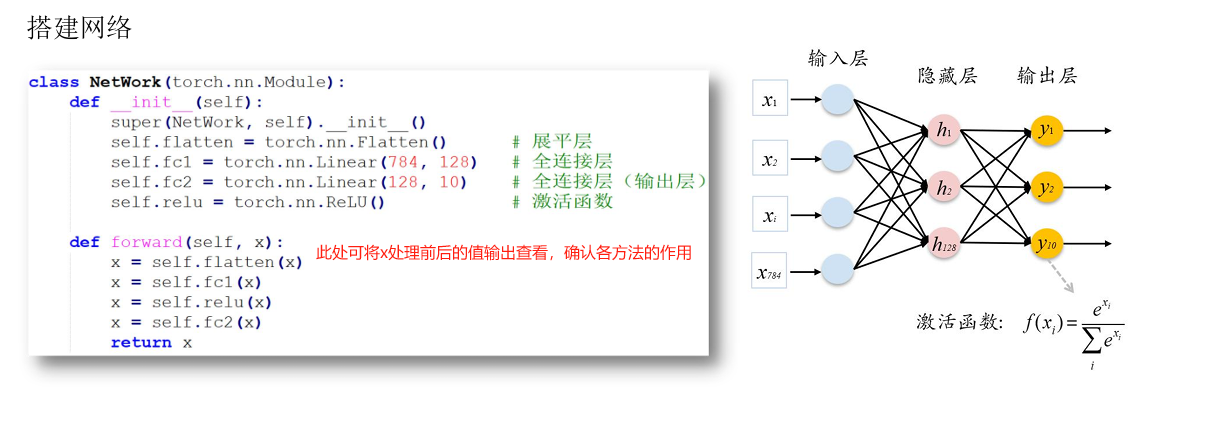





具体可执行代码
1 | |
(1)文件“识别手写数字2.py”内容如下:
1 | |
(2)网络(模型)定义文件“mnist_net_work2.py”如下:
1 | |
(3)模型应用即模型效果的验证,对应的文件“predict2.py”如下:
1 | |
| ID | Name | Required | Description |
|---|---|---|---|
| 1 | enqueue | Y | 判断集群中的空闲资源是否能满足作业调度的基本需求,如果能,则将作业的podgroup设置为 inqueue状态,否则保持podgroup为pending状态。 |
| 2 | allocate | Y | 尝试为inqueue状态的podgroup作业分配资源。 |
| 3 | backfill | N | 尝试为未指明pod资源申请量的作业分配资源。 |
| 4 | preempt | N | 识别高优先级的调度作业。尝试驱逐低优先级的Pod,并为高优先级作业分配资源。 |
| 5 | reclaim | N | 选择资源被其他queue占用的queue,并回收相应资源。 |
| 6 | shuffle | N | 将任务队列中的任务顺序随机化,提高资源利用率、优化调度性能 |
| ID | Name | Arguments | Registered Functions | Description |
|---|---|---|---|---|
| 1 | binpack | * binpack.weight * binpack.cpu * binpack.memory * binpack.resources |
* nodeOrderFn | 尽量将Pod绑定到资源利用率高的节点上, 以减少碎片化。 |
| 2 | conformance | / | * preemptableFn * reclaimableFn |
跳过关键Pod,而不是驱逐它们。 |
| 3 | drf | / | * preemptableFn * queueOrderFn * reclaimFn * jobOrderFn * namespaceOrderFn |
为所有队列提供公平的资源共享。 |
| ID | Name | Arguments | Registered Functions | Description |
| 4 | extender | * extender.urlPrefix * extender.httpTimeout * extender.onSessionOpenVerb * extender.onSessionCloseVerb * extender.predicateVerb * extender.prioritizeVerb * extender.preemptableVerb * extender.reclaimableVerb * extender.queueOverusedVerb * extender.jobEnqueueableVerb * extender.ignorable |
* predicateFn * batchNodeOrderFn * preemptableFn * reclaimableFn * jobEnqueueableFn * overusedFn |
添加外部http server,用 以执行自定义action。 |
| 5 | gang | / | * jobValidFn * reclaimableFn * preemptableFn * jobOrderFn * JobReadyFn * jobPipelineFn * jobStarvingFn |
为作业分配资源时,重点 考虑作业的最低资源需求 和pod最小运行数量,执 行“All or nothing”的调度 策略。 |
| 6 | nodeorder | * nodeaffinity.weight * podaffinity.weight * leastrequested.weight * balancedresource.weight * mostrequested.weight * tainttoleration.weight * imagelocality.weight |
* nodeOrderFn * batchNodeOrderFn |
以自定义的方式对所有节点 进行排序。 |
| ID | Name | Arguments | Registered Functions | Description |
| 7 | numaaware | * weight | * predicateFn * batchNodeOrderFn |
在将pod绑定到node节点时, 重点考虑CPU Numa因素。 |
| 8 | overcommit | * overcommit-factor | * jobEnqueueableFn * jobEnqueuedFn |
将可用资源设置为群集整体 资源的指定倍数。 |
| 9 | predicate | * predicate.GPUSharingEnable * predicate.CacheEnable * predicate.ProportionalEnable * predicate.resources * predicate.resources.nvidia.com/gpu.cpu * predicate.resources.nvidia.com/gpu.memory |
* predicateFn | 添加关于如何为pod调度过滤 node的自定义函数。 |
| 10 | priority | / | * taskOrderFn * jobOrderFn * preemptableFn * jobStarvingFn |
定义调度作业的优先级。 |
| 11 | proportion | / | * queueOrderFn * reclaimableFn * overusedFn * allocatableFn * jobEnqueueableFn |
根据queue的配置,将集群的整 个资源按比例划分到所有的 queue。 |
| ID | Name | Arguments | Registered Functions | Description |
| 12 | sla | * sla-waiting-time | * jobOrderFn * jobEnqueueableFn * JobPipelinedFn |
根据SLA设置对工作负载进行排序。 |
| 13 | task-topology | / | * taskOrderFn * nodeOrderFn |
根据给定策略,将不同角色的Pod绑定到节点上。 |
| 14 | tdm | * tdm.revocable-zone.rz1 * tdm.revocable-zone.rz2 * tdm.evict.period |
* predicateFn * nodeOrderFn * preemptableFn * victimTasksFn * jobOrderFn * jobPipelinedFn * jobStarvingFn |
在不同的时间段内,允许部分节点承接K8s和其他 集群的作业调度。 |
PyTorch框架基础实践
https://jiangsanyin.github.io/2025/03/01/PyTorch框架基础实践/