跟随《大语言模型-赵鑫教授团队》入门大语言模型
一、课程学习内容与打卡要求
https://www.datawhale.cn/learn/summary/107
二、正式课程内容
2.1 第一课 初识大模型
2.1.1 语言模型的发展
ChatPGT于2022年11月底上线,引爆全球关注。
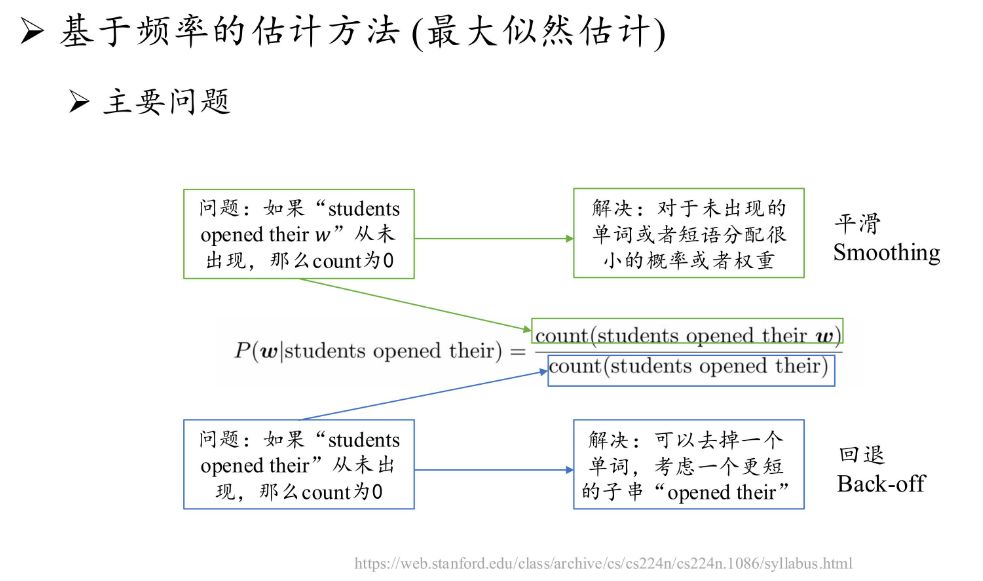
- 语言模型通常是指能够建模自然语言文本生成概率的模型
- 从语言建模到任务求解,这是科学思维的一次重要跃升







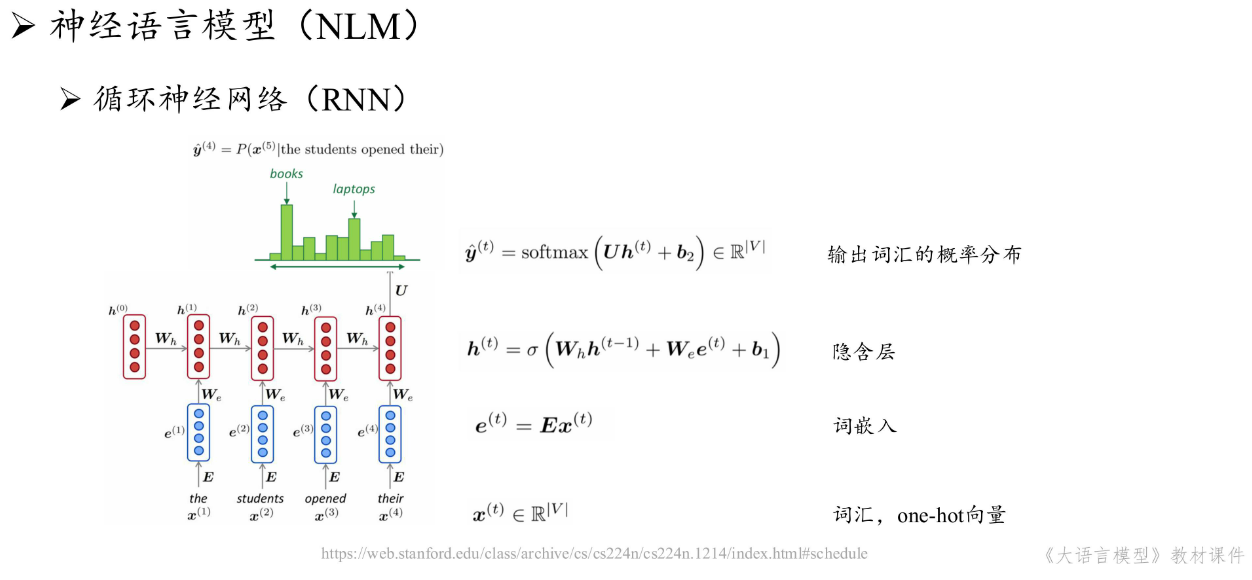

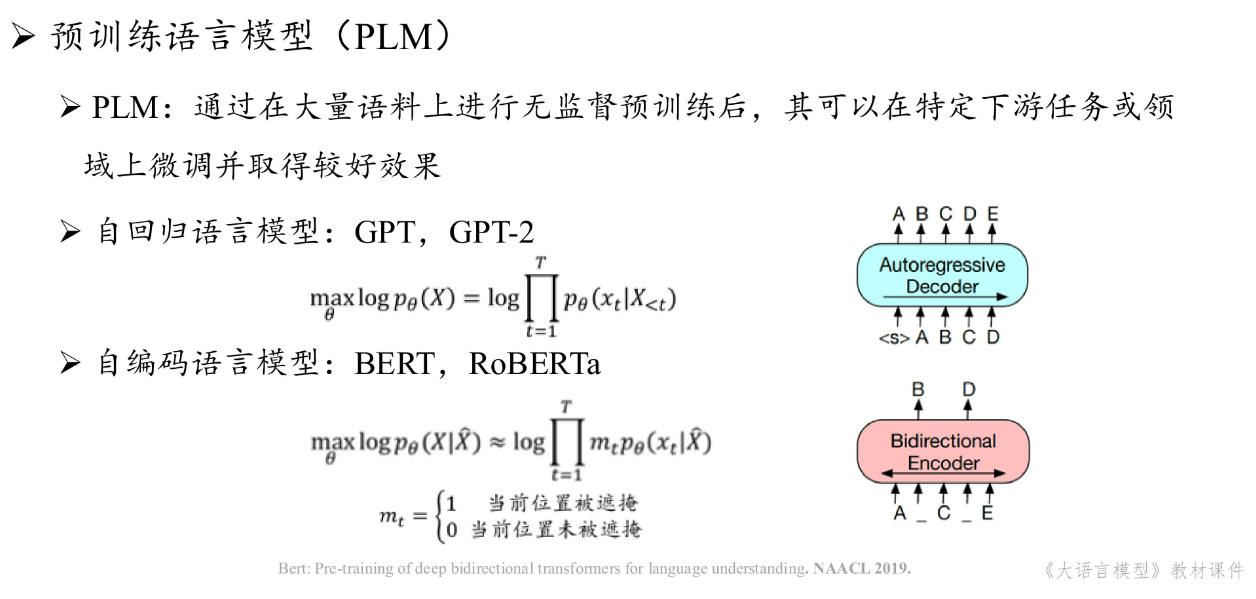


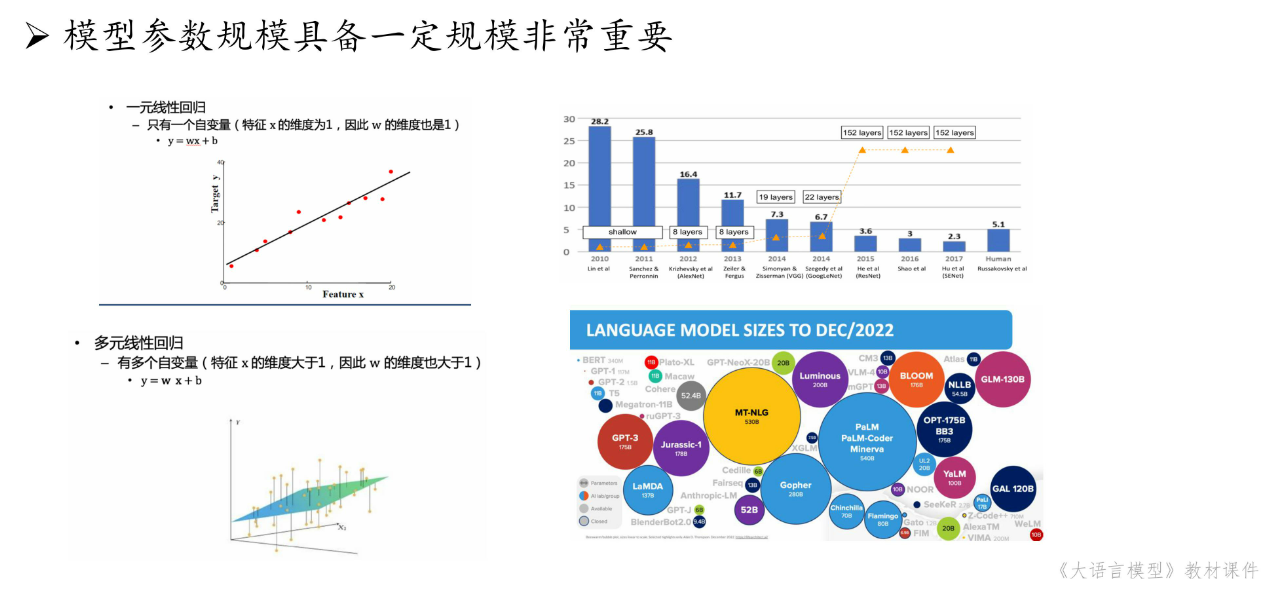

2.1.2 大模型技术基础
大模型:通常是指具有超大规模参数的预训练语言模型。构架上一般使用Transformer解码器构架。其训练包括预训练pre-training(生成base model)与后训练post-training(生成instruct model)

预训练与后训练的主要区别如下:
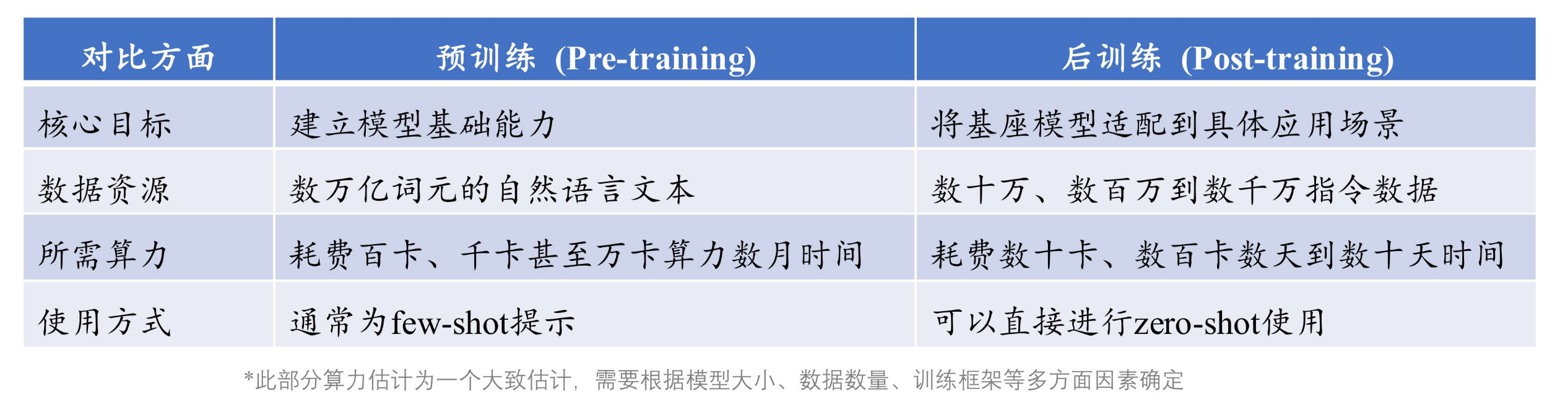
大语言模型构建概览
预训练: 使用与下游任务无关的规模数据进行模型参数的初始训练。
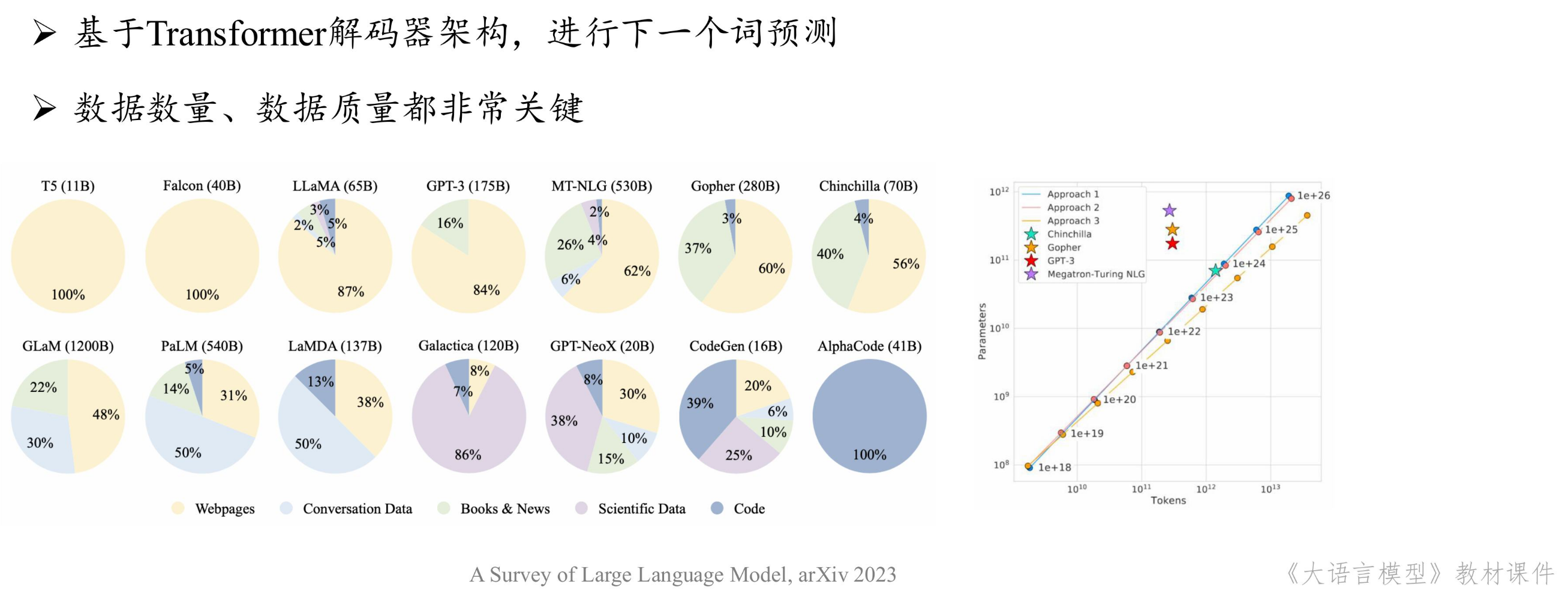
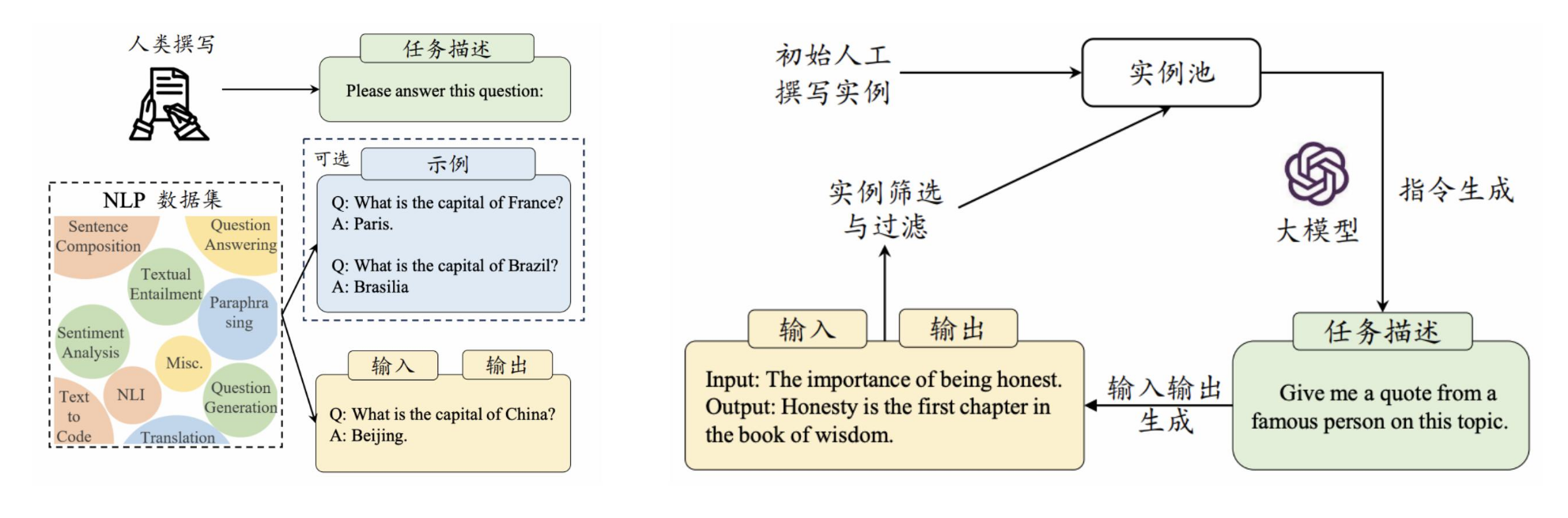
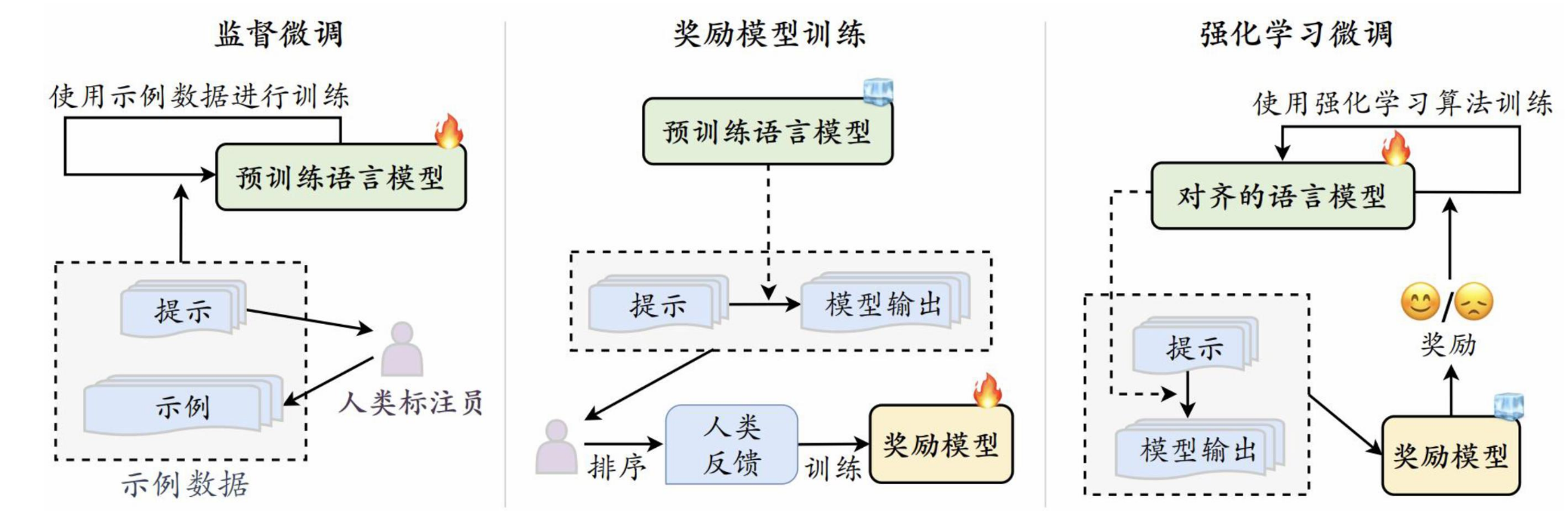
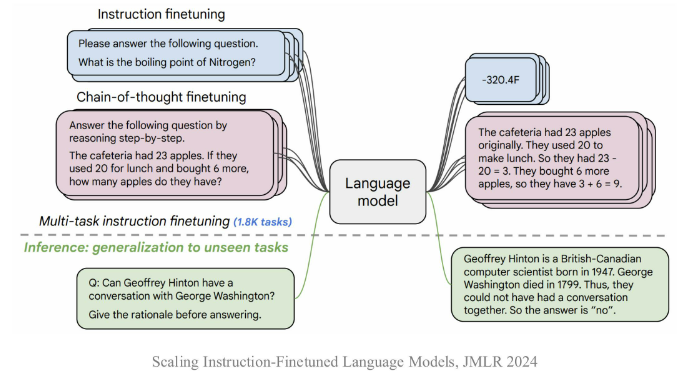
后训练采用的方法一般是指令微调(Instrcution Tuning):
- 指令微调:使用输入与输出配对的指令数据对模型进行微调,提升模型通过问答形式进行任务求解的能力。
- 人类对齐:将大语言模型与人类期望、需求以及价值观对齐,基于人类反馈的强化学习对齐方法RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)
大模型的研发已经已经成为一项系统工程。
扩展定律
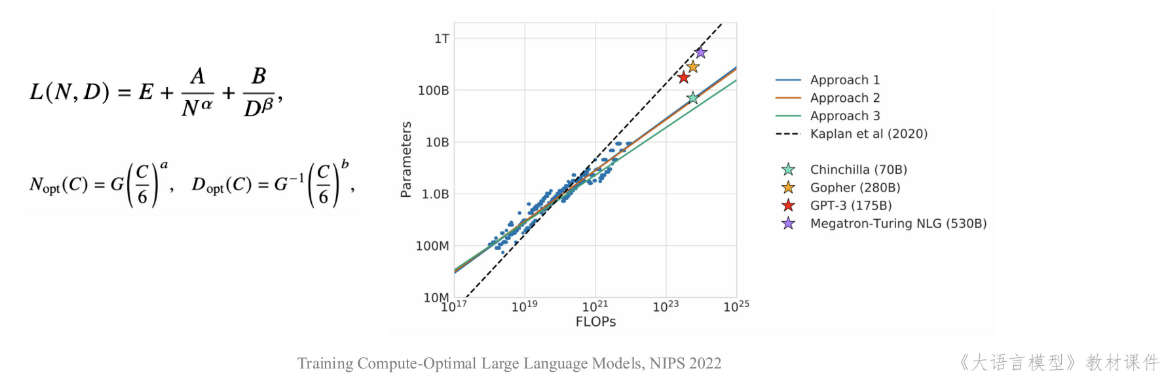
KM扩展定律
- OpenAI团队建立了神经语言模型性能与参数规模(N)、数据规模(D)和计算规模(C)之间的幂等关系,如下所示
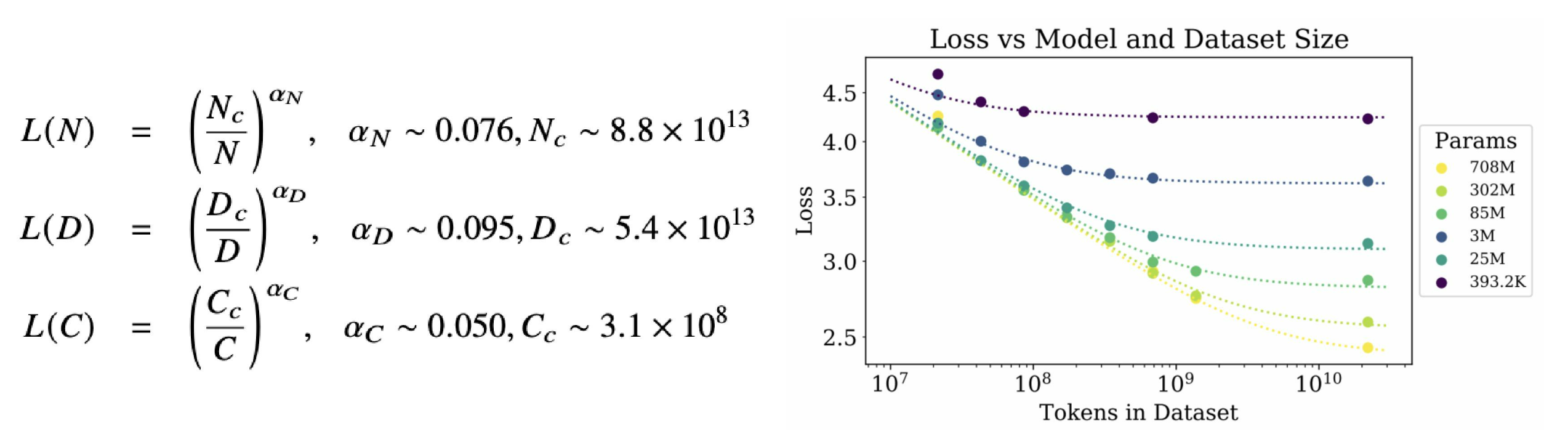
数据规模越大,损失越小。相同的数据规模,参数规模越大,损失越小。
Chinachilla扩展定律
- DeepMind团队于2022年提出了另一种形式的扩展定律,旨在指导大语言模型充分利用给定的算力资源优化训练
深入讨论

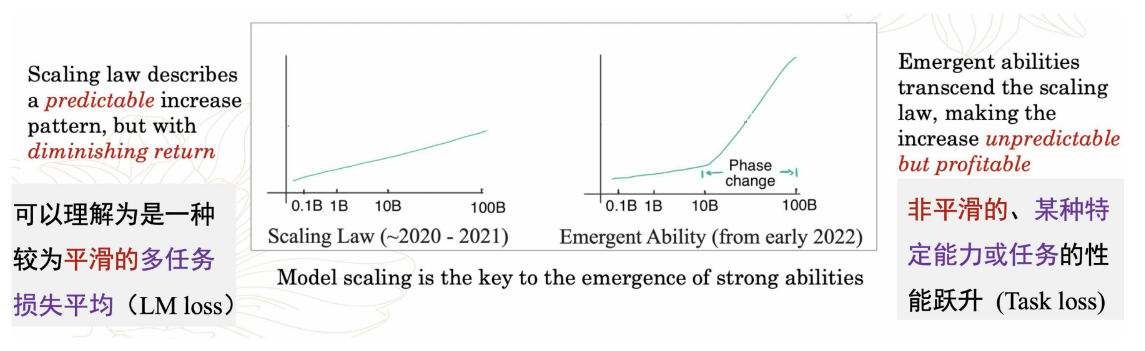
涌现能力
- 什么是涌现能力
- 原始论文定义:“在小型模型中不存在、但在大模型中出现的能力”
- 模型扩展到一定规模时,特定任务性能突然出现显著跃升趋势,远超随机水平
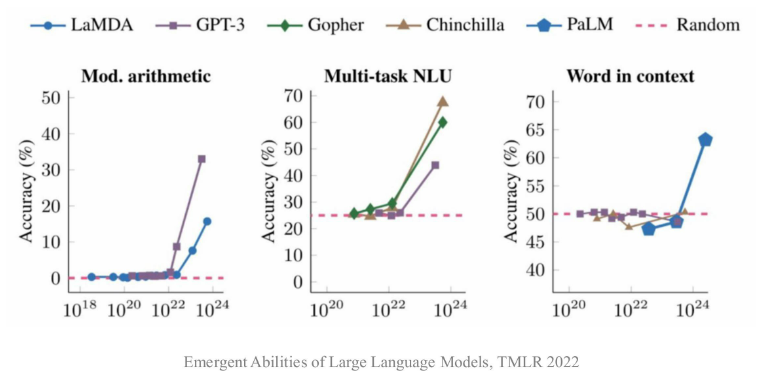
从上图可以看出,将模型参数规模扩展某个量级时,模型性能出现显著提升。
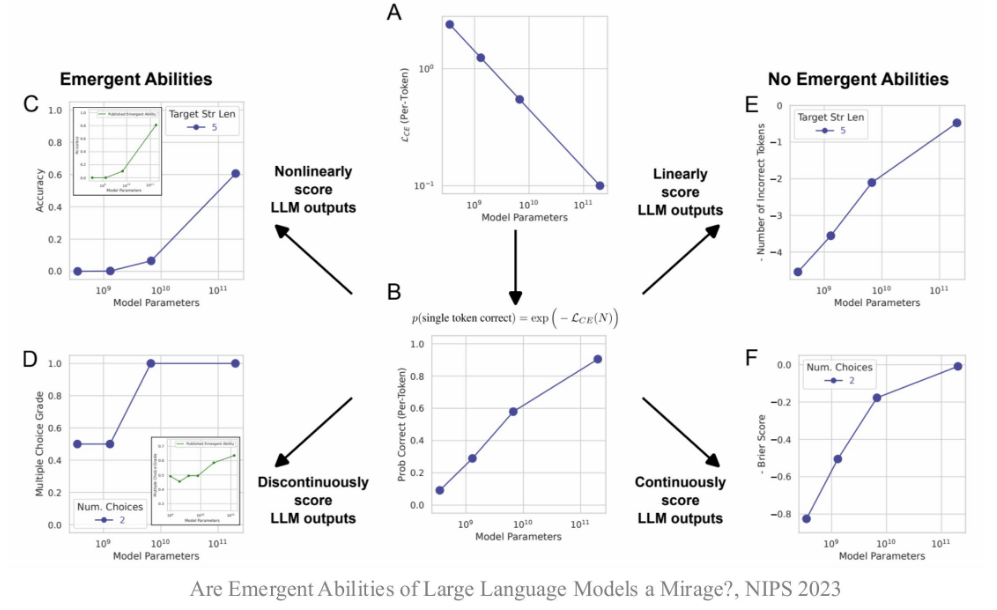
- 涌现能力可能部分归因于评测设置
- 本课程定义其为“代表性能力”,并不区分是否在小模型中存在
- 代表性能力
- 指令遵循(Instruction Following)
- 大语言模型能够按照自然语言指令来执行对应的任务
- 大语言模型能够按照自然语言指令来执行对应的任务
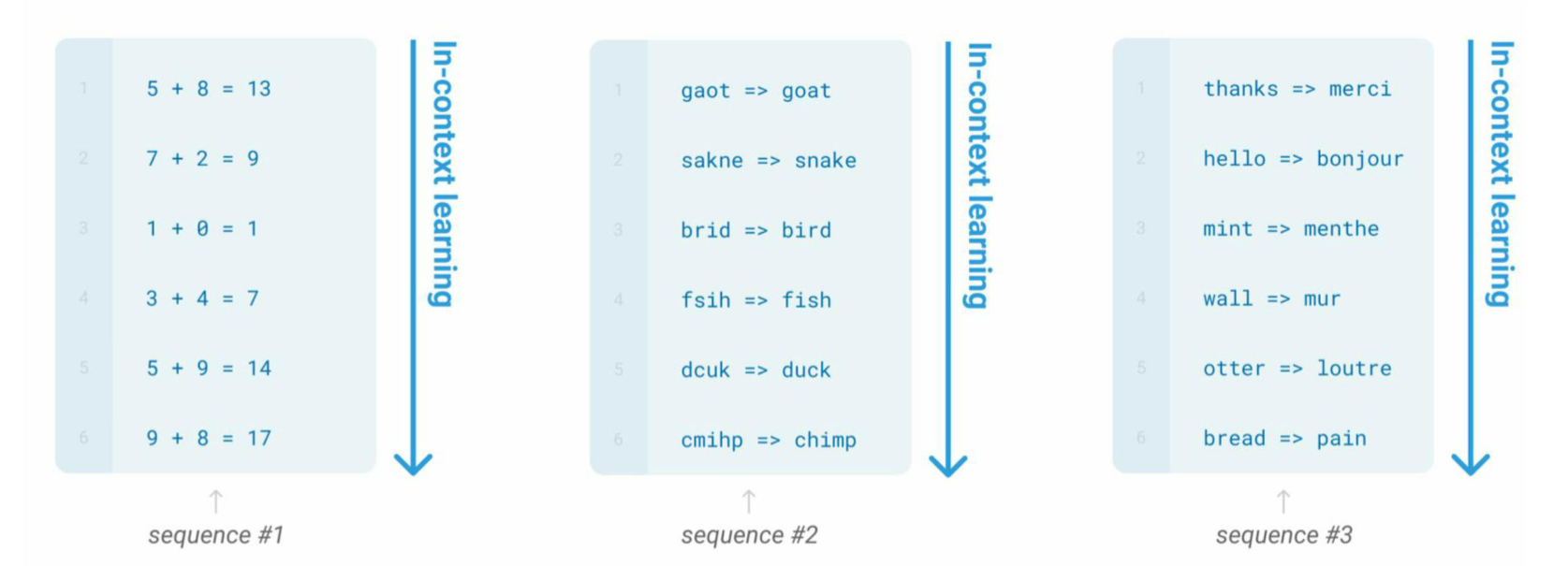
- 上下文学习(In-context Learning)
- 在提示中为语言模型提供自然语言指令和任务示例,无需显式梯度更新就能为测试样本生成预期输出
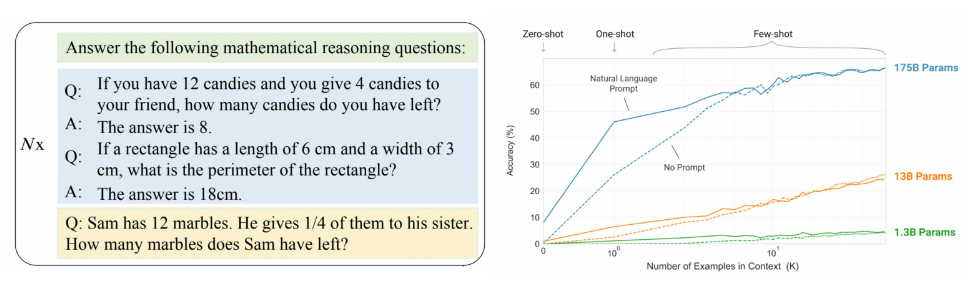
- 逐步推理(Step-by-step Reasoning)
- 在提示中引入任务相关的中间推理步骤来加强复杂任务的求解,从而获得更可靠的答案
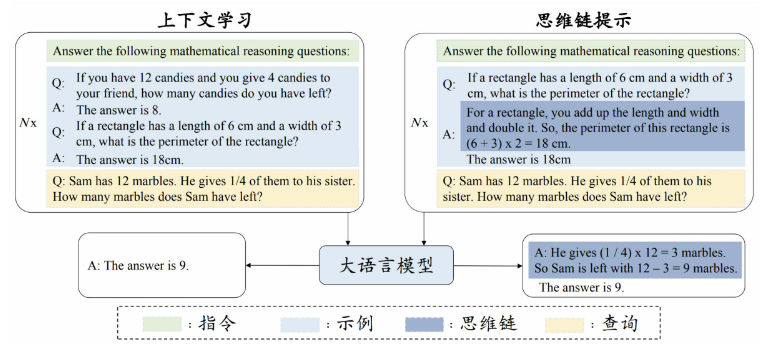
- 指令遵循(Instruction Following)
- 涌现能力与扩展定律的关系
- 涌现能力和扩展定律是两种描述规模效应的度量方法
总结
- 大模型核心技术
- 规模扩展:扩展定律奠定了早期大模型的技术路线,产生了巨大的性能提升
- 数据工程:数据数量、数据质量以及配制方法极其关键
- 高效预训练:需要建立可预测、可扩展的大规模训练架构
- 能力激发:预训练后可以通过微调、对齐、提示工程等技术进行能力激活
- 人类对齐:需要设计对齐技术减少模型使用风险,并进一步提升模型性能
- 工具使用:使用外部工具加强模型的优势,拓展其能力范围
2.1.3 GPT与DeepSeek模型介绍
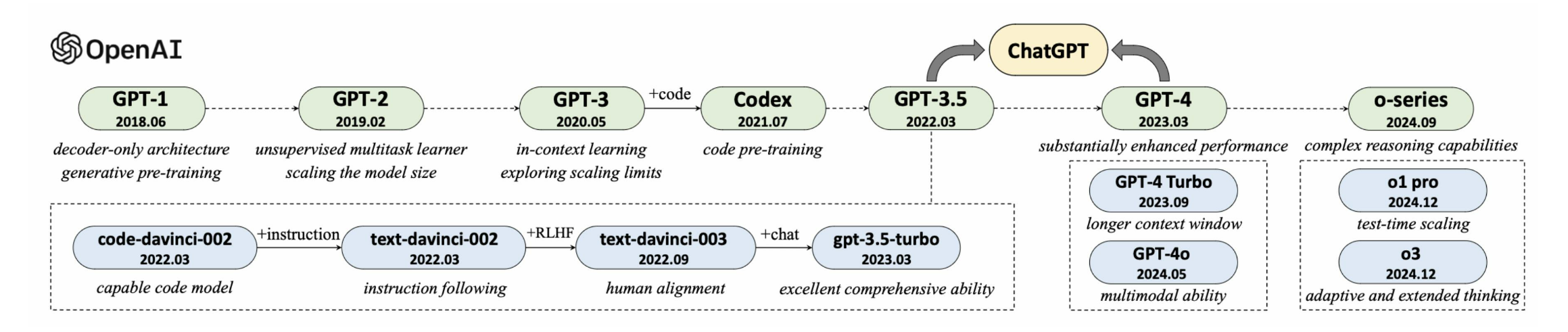
GPT系列模型并非偶然出现
- GPT系列模型成体系推进

GPT系列模型的技术演变
GPT系列模型发展历程
小模型:GPT-1,GPT-2
大模型:GPT-3,CodeX,GPT-3.5,GPT-4
推理大模型:o-series
- GPT-1(1.1亿参数)
纯代码Transformer架构
预训练后针对特定任务微调
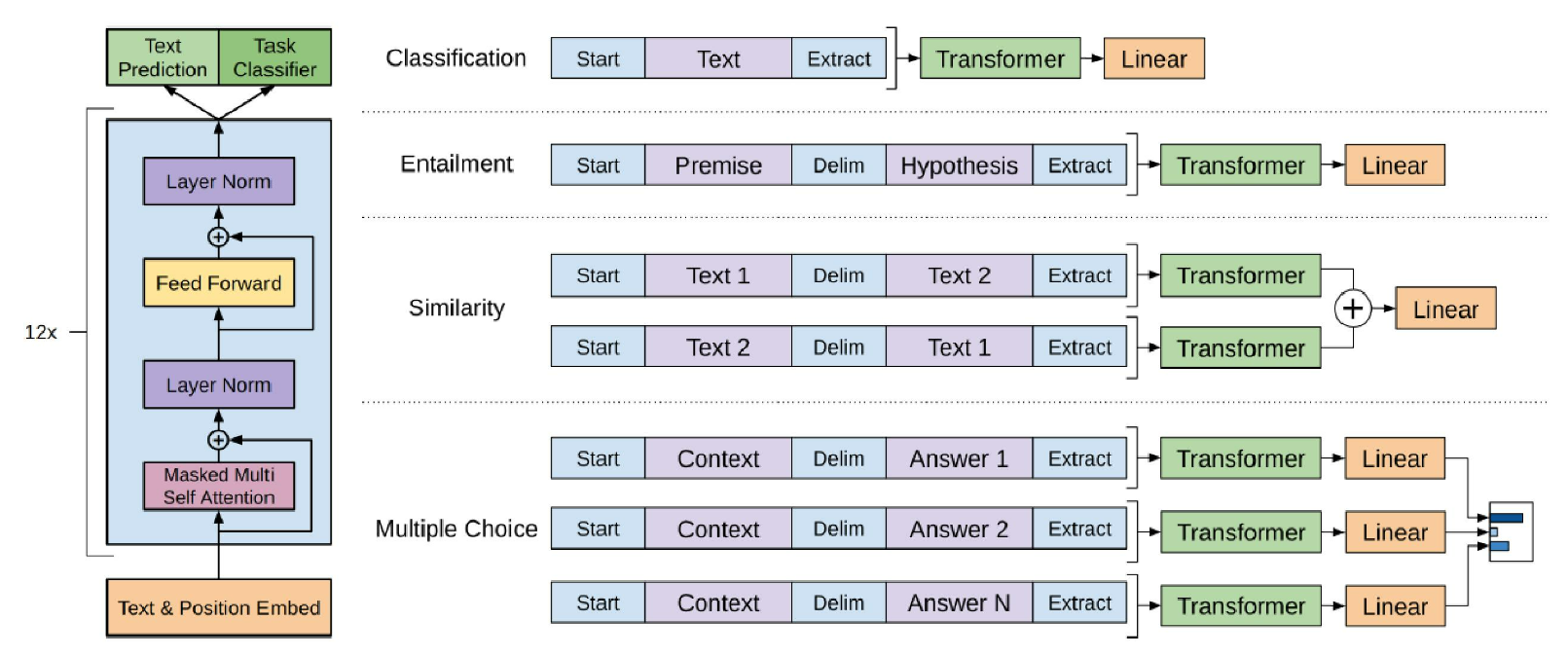
- GPT-2(15亿参数)
将任务形式统一为单词预测:
Pr(output|input, task)预训练与下游任务一致
使用提示进行无监督任务求解
初步尝试了规模扩展
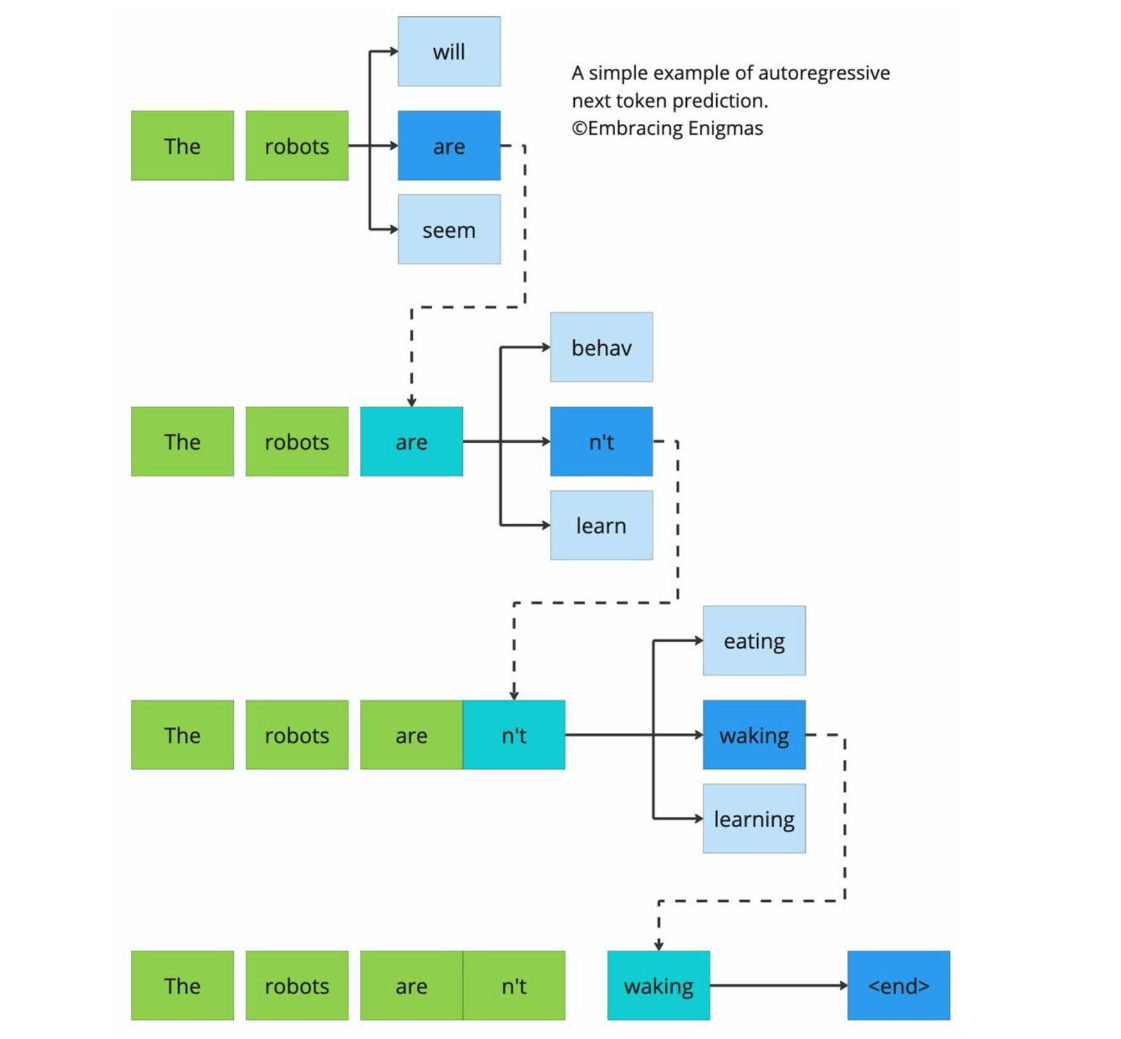
- GPT-3
模型规模达到1750亿参数 涌现出上下文学习能力
- CodeX
代码数据训练 推理与代码合成能力
- WebGPT
大语言模型使用浏览器
- InstructGPT
大语言模型与人类价值观对齐 提出RLHF算法

- ChatGPT
基于 InstructGPT相似技术开发,面向对话进行优化
- GPT-4
推理能力显著提升,建立可预测的训练框架
可支持多模态信息的大语言模型
- GPT-4o
原生多模态模型,综合模态能力显著提升
支持统一处理和输出文本、音频、图片、视频信息
- o系列模型(应该是指GPT-4o)
推理任务上能力大幅提升
长思维链推理能力
- o-series(应该是指GPT-o1/GPT-o3)
类似人类的“慢思考”过程

DeepSeek系列模型技术演变
- DeepSeek系列模型发展历程
训练框架:HAI-LLM 语言大模型:DeepSeekLLM/V2/V3、Coder/Coder-V2、Math 多模态大模型:DeepSeek-VI 推理大模型:DeepSeek-R1

DeepSeek实现了较好的训练框架与数据准备
- 训练框架HAI-LLM(发布于2023年6月)
大规模深度学习训练框架,支持多种并行策略
三代主力模型均基于该框架训练完成
- 数据采集
V1和Math的报告表明清洗了大规模的CommonCrawl,具备超大规模数据处理能力
Coder的技术报告表明收集了大量的代码数据
Math的技术报告表明清洗收集了大量的数学数据
VL的技术报告表明清洗收集了大量多模态、图片数据
DeepSeek进行了重要的网络架构、训练算法、性能优化探索
V1探索了scaling law分析(考虑了数据质量影响),用于预估超参数性能
V2提出了MLA高效注意力机制,提升推理性能
V2、V3都针对MoE架构提出了相关稳定性训练策略
V3使用了MTP(多token预测)训练
Math 提出了PPO的改进算法GRPO
V3详细介绍Infrastructure的搭建方法,并提出了高效FP8训练方法
- DeepSeek-V3
671B参数(37B激活),14.8T训练数据
基于V2的MoE架构,引入了MTP和新的复杂均衡损失
对于训练效率进行了极致优化,共使用2.788MH800GPU时
- DeepSeek-R1
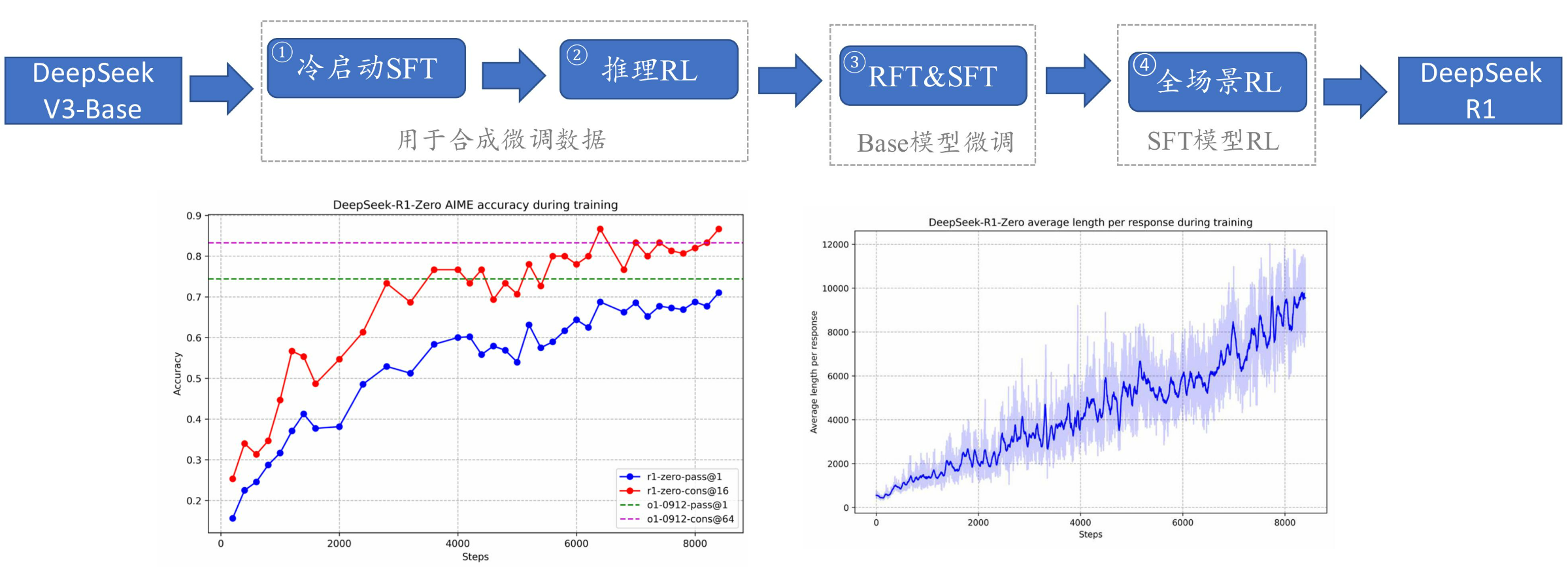
- DeepSeek-V3和DeepSeek-R1均达到了同期闭源模型的最好效果
开源模型实现了重要突破
- 为什么 DeepSeek会引起世界关注
打破了OpenAI闭源产品的领先时效性(国内追赶GPT-4的时间很长,然而复现o1模型的时间大大缩短)
达到了与OpenAI现有API性能可比的水平
- 为什么 DeepSeek 会引起世界关注
中国具备实现世界最前沿大模型的核心技术
模型开源、技术开放
2.2 第二课 模型构架
PPT看了一遍,但看得有点云里雾里,暂时也没有截图或做PPT相关的笔记了。 只能又再去看书中相关章节,阅读过程中看到一些概念,忘记了或不知道,复习或学习记录在此。
Transformer模型(介绍)
以下主要学习Transformer模型的构架。
已有的大语言模型主要是基于Transformer模型进行设计与开发的。
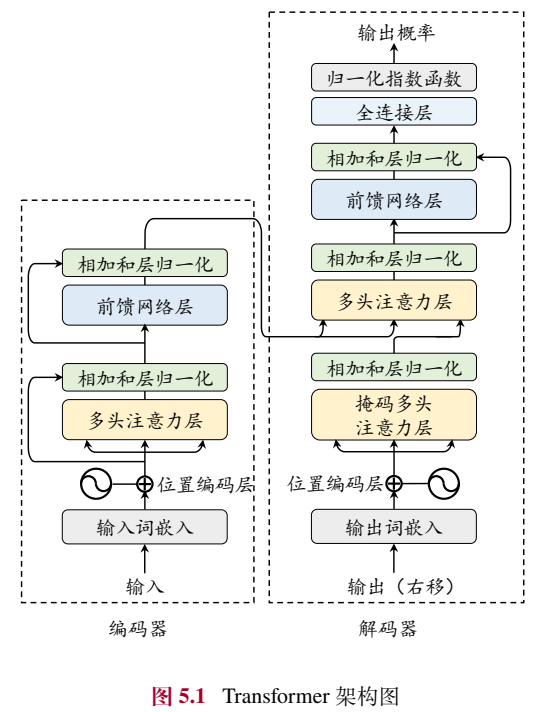
Transformer是由含有多头注意力和前馈网络的子模块堆叠而成的神经网络模型。其主要包含输入编码层、多头注意力层和前馈网络层。
输入编码层
在Transformer模型中,输入的词元序列 \[
𝒖 = [𝑢_1, 𝑢_2, . . . , 𝑢_𝑇]
\] (词元(词元与词向量的概念,参考 Transformer构架中专业名词
)序列,即由多个词元组成的序列。)经过一个输入嵌入模块(input embedding
module)转化为向量序列。为了建模词汇本身的语义信息,每个词元在输入嵌入模块中被映射为一个可用于计算与学习的词向量vt。另外,为了表示建模序列中元素的位置信息,Transformer引入了位置编码(position
emdedding,PE)。给定一个词元ut,位置编码根据其在输入中的绝对位置分配一个对应的位置向量pt,将词向量与对应的位置向量直接相加,就可以得到一个输入嵌入表示序列:
\[
𝑿 = [𝒙_1, . . . , 𝒙_𝑇],其中 𝒙_𝑡 = 𝒗_𝑡 + 𝒑_𝑡
\] 这样,就将一个自然语言输入序列(如“I love
NLP.”)示成一个输入嵌入表示序列 。
。
Transformer框架可以使用位置编码pt建模不同词元的位置 信息。因为这种位置编码仅由词元对应的位置决定,因此也被称为绝对位置编码,绝对位置编码方法限制了Transformer模型处理其长文本的能力。
多头注意力层
多头注意力机制是Transformer模型的核心技术,能够直接建模任意距离之间的交互关系。相比之下,CNN是迭代地利用前一个时刻的状态更新当前时刻的状态,所以在处理长序列时,可能会出现梯度爆炸或梯度消失的问题;而RNN中,只有位于同一个卷积核内的词元可以直接进行交互,需要通过堆叠卷积层来实现远距离的信息交换。
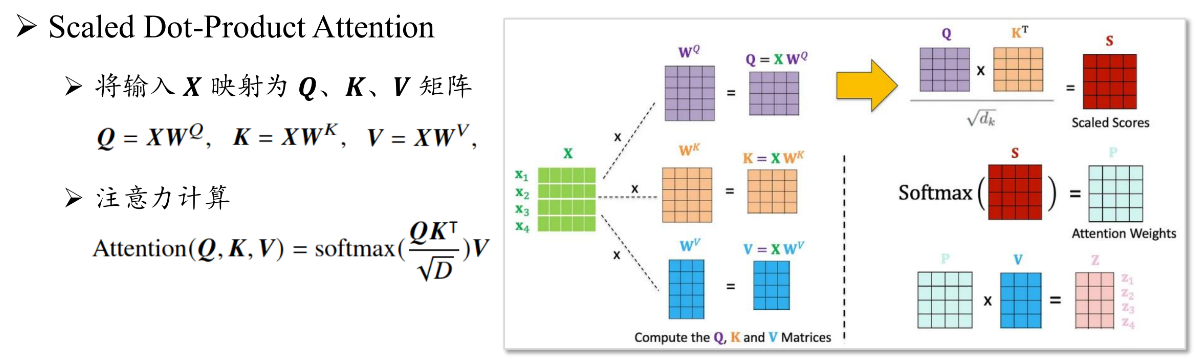
一个多头注意力通常由多个注意力模块组成。每个注意力模块中,会将输入的嵌入序列映射成为相应的查询(query,Q)、键(key,K)、值(value,V)三个矩阵。之后每个查询与所有键进行点积运算,并使用softmax函数计算注意力分数。 再然后,这些分数将用于计算值向量的加权线性组合,以得到最终输出。其一致过程如下: \[ \begin{aligned} Q = XW^Q\qquad\qquad\qquad(5.2)\\ K = XW^K\qquad\qquad\qquad(5.3)\\ V = XW^V\quad\quad\quad\quad\quad\quad(5.4)\\ attention(\mathbf{Q,K,V}) = softmax(\frac{QK^T}{\sqrt{D}})V\quad\quad\quad\quad\quad\quad(5.5)\\ 公式(5.5)中,通过除以\sqrt{D}进行数值缩放,其中D是键对应的向量维度。 \end{aligned} \] 多头注意力层由多个注意力模块组成。每个注意力模块都有不同的映射参数,即多头注意力机制引入 了N组结构相同但映射参数不同的注意力模块(注意力头,attention head)。在每个注意力头中,输入序列被映射为一组查询、键、值,通过使用上述公式独立计算并输出。然后不同的注意力头的输出被拼接在一起,并通过一个权重矩阵WO 映射为最终输出: \[ \begin{aligned} MHA=Concat(head_1,head_2,...,head_N)W^O\quad\quad\quad\quad\quad\quad(5.6)\\ head_n=Attention(\mathbf{Q,K,V})=Attention(XW^Q_n,XW^K_n,XW^V_n)\quad\quad\quad\quad\quad\quad(5.7) \end{aligned} \] 注意力机制能够直接建模序列中任意两个位置之间的关系,比传统神经网络具有更强的长序列建模能力。此外, 因为注意力的计算过程中是矩阵的相关运算,对硬件的并行计算具有较好的适配性,比如NVIDIA GPU这类加速卡设备就能高效地支持大规模Transformer模型的参数优化。
点积: \[ \begin{aligned} 对于向量&a与向量b(要求两向量的维度一样):\\ &a=[a_1,a_2,...,a_n]\quad\quad b=[b_1,b_2,...b_n]\\ &a和b的点积公式为:a•b=a_1b_1+a_2b_2+...+a_nb_n \end{aligned} \]
softmax函数:https://zhuanlan.zhihu.com/p/105722023、https://zh.wikipedia.org/zh-cn/Softmax%E5%87%BD%E6%95%B0
该函数的形式通常按下面的式子给出: \[ {\displaystyle \sigma (\mathbf {z} )_{j}={\frac {e^{z_{j}}}{\sum _{k=1}^{K}e^{z_{k}}}}} for j = 1, …, K. \]
1 | |
前馈网络层
为了学习复杂的函数映射关系,Transformer引入了前馈网络层(feed forward network,FFN),对嵌入序列(就是输入编码层得到的嵌入表示序列)进行非线性变换。详细地说,给定输入X,Transformer模型中的前馈神经层由两个线性变换和一个非线性变换函数 组成: \[ \begin{aligned} FFN(\mathbf{X})=σ(\mathbf{XW^U} + \mathbf{b_1})\mathbf{W^D} + \mathbf{b_2}\qquad\qquad\qquad(5.8)\\ 其中W^U∈R^{H×H^′} 和 W^D∈R^{H^′×H} 分别是第一层和第二层的线性变换权重矩阵,b_1∈R^{H^′}和b_2∈R^{H} 是偏置项,σ是激活函数 \end{aligned} \] 在原始的Transformer模型中,采用了ReLU作为激活函数。前馈网络层通过激活函数引入了非线性变换,提升了模型的表达能力,从而能够更好地建模复杂的交互关系。
为什么通过引入非线性变换,能够模型的表达能力?
线性变换与非线性变换:
可参考:https://blog.csdn.net/qq_35468747/article/details/122005322、https://www.zhihu.com/question/298320067 \[ \begin{aligned} 如果一个变换满足以下条件,则为线性变换:\\ T是某函数,它使得映射V → W 成立,并且满足以下条件:\\ T(x+y) =T(x)+T(y)\\ T(ax) =aT(x)\\ 其中x , y ∈ V ,a ∈ R \end{aligned} \] 识别给定函数f ( x ) f(x)f(x)是否为线性变换非常简单,只需要查看f ( x )中的每一项是否都是x与一个数的乘积,如果是,f 则是线性变换。
f(x,y,z)=(3x−y,3z,0,z−2x) 此函数是一个线性变换(可以写成矩阵相乘的形式进行查看)
g(x,y,z)=(3x−y,3z+2,0,z−2x) ,此函数则不是一个线性变换。因为在函数g 中,第二个分量为3 z + 2,2 是一个常数,并不包含输入向量( x , y , z )中的任何分量
在几何直观上,线性变换有如下性质:
变换前是直线,变换后仍是直线
原点保持固定不动
编码器
Transformer模型中,编码器的大致构架如下图左侧部分所示内容:
编码器的作用是将每个输入词元都编码成一个上下文语义相关的表示向量。编码器结构由多个相同的层堆叠而成,其中每一层都包含多头自注意力模块和前馈网络模块。在注意力和前馈网络后,模型使用层归一化和残差连接来加强模型的训练稳定度。
其中,残差连接将输入与该层的输出(比如对于多头注意力层而言,这是多头注意力层的输入与输出)相加,实现了信息在不同层的直接传递,从而缓解梯度爆炸或梯度消失的问题。
而层归一化,则是对每个模块的的输出进行重新缩放,提升模型的训练稳定性。
编码器接受经过位置编码层的词嵌入序列 𝑿 作为输入,通过多个堆叠的编码器层来建模上下文信息,进而生成整个输入序列的编码表示。
由于输入数据是完全可见的,编码器中的注意力模块通常采用双向注意力,每个位置的词元表示能够有效融合来自上下文的语义信息。
在编码器-解码器构架中,编码器的输出将作为解码器的输入,进行后续计算。用公式表示如下,第l(是L的小写)层编码器的数据处理过程如下所示: \[ \begin{aligned} &𝑿^′_𝑙 = LayerNorm(MHA(𝑿_{𝑙−1}) + 𝑿_{𝑙−1}) \\ &𝑿_𝑙 = LayerNorm(FFN(𝑿^′_𝑙) + 𝑿^′_𝑙)\quad\quad\quad\quad\quad\quad(5.9) \\ \end{aligned} \]
\[ \begin{aligned} 其中𝑿_{𝑙−1}和𝑿_{𝑙}分别表示该Transformer层的输入与输出,\\ 𝑿^′_𝑙 是经过多头注意力模块后的中间表示,LayerNorm表示层归一化 \end{aligned} \]
架构图解析:
- 输入词嵌入:将输入文本转换为向量表示。
- 位置编码:为每个输入添加位置信息,以便模型能够区分不同位置的词。
- 多头注意力层:用于捕捉输入序列中不同位置之间的依赖关系。
- 前馈网络层:用于对输入进行非线性变换。
- 相加和层归一化:用于稳定训练过程。
- 输出概率:最终输出的概率分布,用于预测下一个词或分类任务。
解码器
Transformer模型中,解码器的大致构架如下图右侧部分所示内容:
Transformer 架构中的解码器基于来自编码器编码后的最后一层的输出表示以及已经由模型生成的词元序列,进行后续内容的生成。与编码器类似,解码器也是由多个相同的层堆叠而成,每个层都包含相同类型的组件。
与编码器不同的是,解码器需要在计算注意力时引入掩码操作,以保证生成目标序列时不依赖于未来信息(防止当前位置看到未来的输出)。
解码器还引入了交叉注意力(cross attention)来关注编码器输出的中间状态XL (用于捕捉解码器和编码器之间的依赖关系)。
与编码器类似,解码器的每个模也采用了层归一化与残差连接(残差连接有助于梯度传播,层归一化则用于稳定训练过程)。
在经过解码器之后,模型会通过一个全连接层将输出映射到大小为 𝑉 的目标词汇表的概率分布,并基于相应的解码策略生成预测词元。
训练过程中,编码器可以对输入目标进行并行训练;而在生成过程中,解码器需要通过自回归的方式逐步生成完整的目标序列。解码器的数据处理流程如下公式所示: \[ \begin{aligned} &𝒀^′_𝑙 = LayerNorm(MaskedMHA(𝒀_{𝑙−1}) + 𝒀_{𝑙−1}),\\ &𝒀^{′′}_𝑙 = LayerNorm(CrossMHA(𝒀^′_𝑙, 𝑿_𝐿) + 𝒀^′_𝑙),\\ &𝒀_𝑙 = LayerNorm(FFN(𝒀^{′′}_𝑙) + 𝒀^{′′}_𝑙)\quad\quad\quad\quad\quad\quad(5.10) \end{aligned} \]
\[ \begin{aligned} 其中,𝒀_{𝑙−1} 和 𝒀_{𝑙} 分别是该 Transformer 层的输入和输出,𝒀^′_𝑙 和 𝒀^{′′}_𝑙 是该层中输入\\ 经过掩码多头注意力 MaskedMHA 和交叉多头注意力 CrossMHA 模块后的中间表示,\\ LayerNorm 表示层归一化。然后将最后一层的输出 𝒀_𝐿 映射到词表的维度上:\\ 𝑶 = softmax(𝒀_𝐿𝑾^𝐿)\quad\quad\quad\quad\quad\quad(5.11)\\ \\ 其中,𝑶∈R^{T×V}是模型的最终输出(V是词汇表大小),代表下一个词元在词表上的概率分布,\\ W^L∈R^{H×V}是将输出映射到词表维度的参数矩阵,而𝒀_𝐿𝑾^𝐿是softmax函数的输入,通常称为logits \end{aligned} \]
(模型)详细配置
Transformer模型的四个核心模块包括:归一化(归一化方法与归一化配置)、激活函数、位置编码、注意力机制。
归一化方法
为了缓解训练损失不稳定的问题,归一化方法被提出。原始的Transformer模型主要使用层归一化方法(layer normolization,LN),后续出现了其他一些改进的变种归一化方法,如均方根归一化(root mean square layer normolization,RMS-Norm)和DeepNorm。
LayerNorm,在早期,批次归一化(batch normolization,BN)被广泛使用,但此归一化方法不能有效处理可变长度的序列数据和小批次数据。针对此问题,层归一化技术被提出,它针对数据进行逐层归一化,也就是说它会计算每一层量激活值的均值 μ 和方差 σ ,重新调整激活值的中心,并通过参数 γ 和 β 进行缩放: \[ \begin{aligned} LayerNorm(x)=\frac{x-μ}{σ}·γ + β\quad\quad\quad\quad(5.12)\\ μ=\frac{1}{H}{\sum _{i=1}^Hx_i },\quad\quadσ=\sqrt{\frac{1}{H}{\sum _{i=1}^H(x_i-μ)^2 }}\quad\quad\quad\quad(5.13)\\ \end{aligned} \]
RMS-Norm。为了提升归一化的训练速度,RMS-Norm只使用激活值总和的均方根RMS(·)对激活值进行缩放。使用RMS-Norm的Transformer模型相比使用LayerNorm训练的模型在训练速度与性能上均具有一定优势。比如 Gopher与Chinchilla模型都采用了RMS-Norm,其计算分工如下: \[ \begin{aligned} RMSNorm(x)=\frac{x}{RMS(x)}·γ \quad\quad\quad\quad(5.14)\\ RMS(x)=\sqrt{\frac{1}{H}{\sum _{i=1}^H(x_i)^2 }}\quad\quad\quad\quad(5.15)\\ \end{aligned} \]
DeepNorm。为了进一步稳定深层Transformer的训练,DeepNorm在LayerNorm的基础上,在残差连接中对之前的激活值x按照一定比例 α 进行缩放,能更新地支持层数扩展。其计算公式如下: \[ DeepNorm(x)=LayerNorm(α·x + Sublayer(x))\quad\quad\quad\quad(5.16)\\ \] 其中Sublayer表示Transformer层中的前馈神经网络或注意力模块。比如GLM-130B就采用了DeepNorm作为归一化技术。
归一化模块位置
不仅归一化方法对训练稳定性有影响,归一化模块的位置对于训练稳定性也具有重要影响。
归一化模块的位置通常有三种选择,分别是层后归一化(post-layer normolization,Post-Norm)、层前归一化(pre-layer normolization,Pre-Norm)和夹心归一化(sandwich-layer normolization,Sandwich-Norm)。它们相对于注意力层与残差连接层的位置分别如下所示:
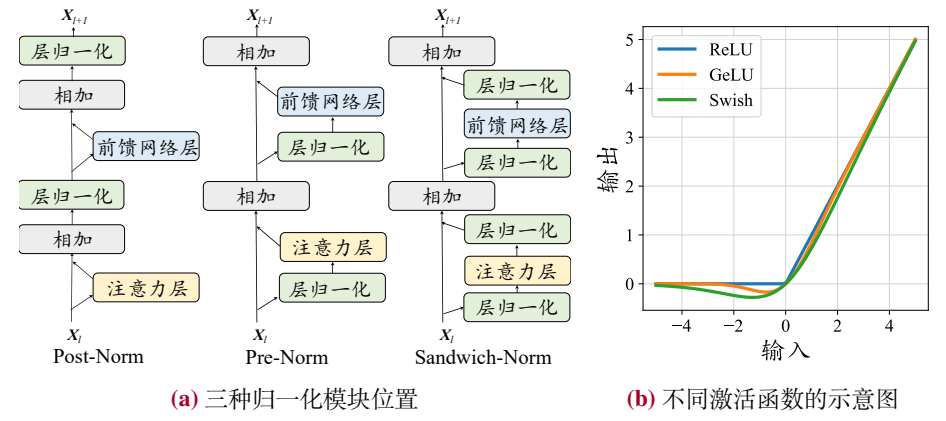
Post-Norm。原始的Transformer模型就是使用Post-Norm归一化技术,即将归一化模块放置在残差连接之后,公式表达如下: \[ Post﹣Norm(x)=Norm(x+Sublayer(x))\quad\quad\quad\quad(5.17)\\ \] 其中Norm代表任意一种具体的归一化方法。Post-Norm具有诸多优势:(1)有助于加快神经网络的收敛速度,防止模型出现梯度爆炸或梯度消失的问题,从而减少训练时间。(2)可以降低神经网络对于超参数(初始化参数、学习率等)的敏感性,使得神经网络更容易进行调优。
但是由于输入层附近的梯度可能较大,Post-Norm有时会引发训练不稳定的现象 。因此一般不单独使用,而是跟其他策略结合使用。
Pre-Norm。此归一化方法将归一化模块放置在每个子层之前。公式表示如下: \[ Pre﹣Norm(x)=x+ Sublayer(Norm(x))\quad\quad\quad\quad(5.18)\\ \] 同样地,Norm也是表示任意一种归一化方法。通过在每个子层之前添加了一个归一化模块,针对每个模块的输入进行归一化,可以缓解梯度爆炸或梯度消失的问题。 此外,Pre-Norm在最后一个Transformer层之后还额外添加了一个LayerNorm。
相对于Post-Norm来说,Pre-Norm虽然在性能上略有逊色,但增加了训练过程中的稳定性,因为很多主流的大模型都采用了Pre-Norm。
Sandwich-Norm。在Pre-Norm的基础上,Sandwich-Norm在残差连接之前增加了额外的LayerNorm,主要还是为了避免层输出数值爆炸的情况。公式表示如下: \[ Sandwich﹣Norm(x)=x+Norm(Sublayer(Norm(x)))\quad\quad\quad\quad(5.19)\\ \] 在某种程度上,Sandwich-Norm可以看作是Post-Norm与Pre-Norm两种方法的组合。虽然从理论上分析好像会得到两种方法的优势即取得更好的归一化效果,但实际情况表明它有时仍然无法保证LLM的训练稳定性,甚至会引发训练崩溃的问题。