一、配置语言与时区
image-20250603162838074
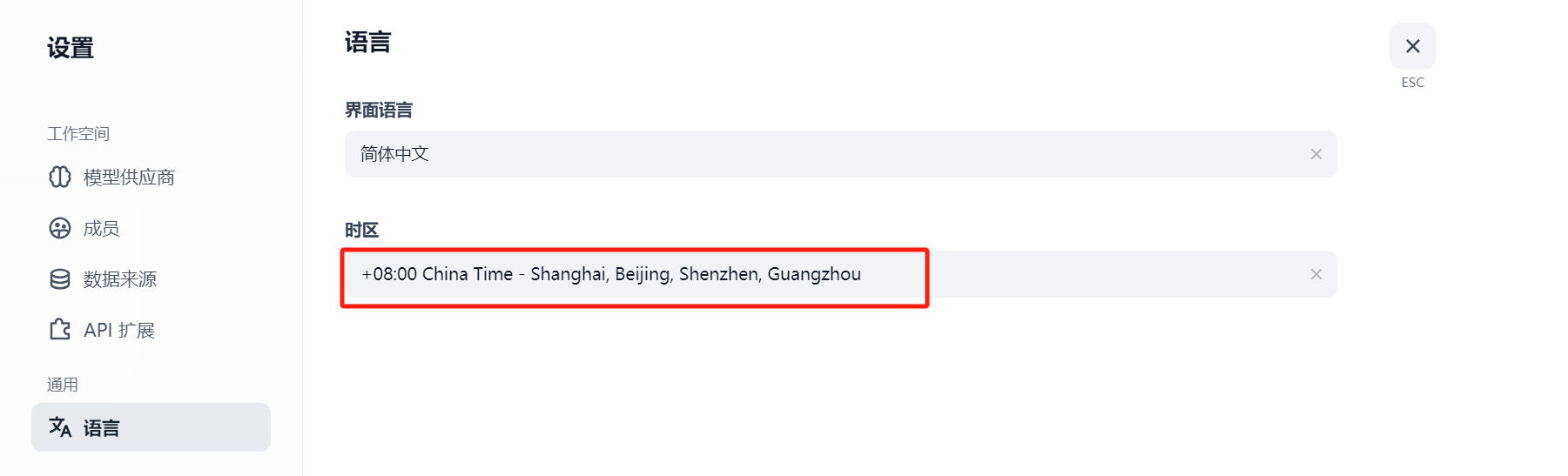
从默认的西五区纽约时间改成东八区北京时间:
image-20250603163057486
二、安装配置模型供应商
2.1 安装模型供应商
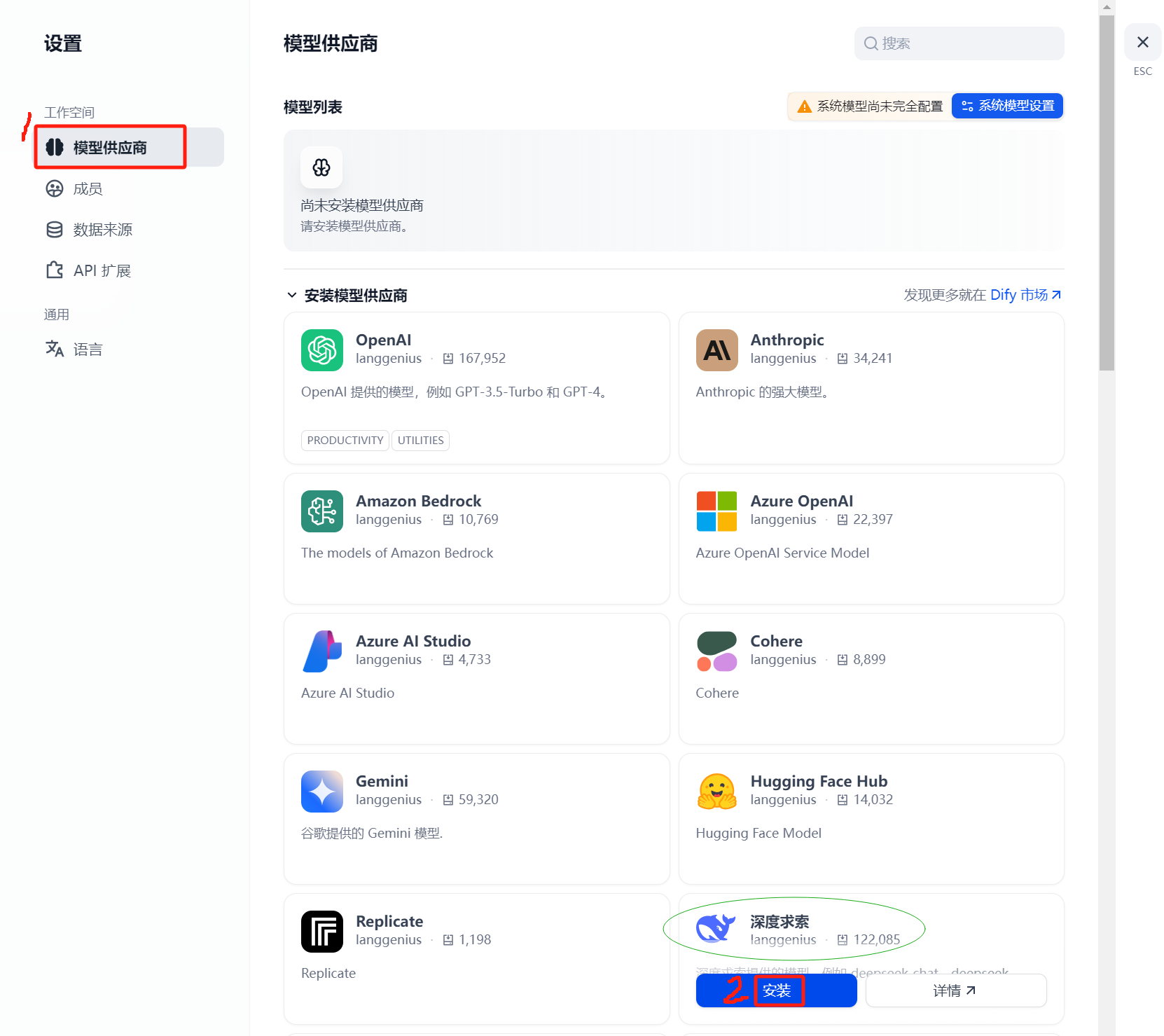
2.1.1 以在线方式安装模型供应商
image-20250603150122644
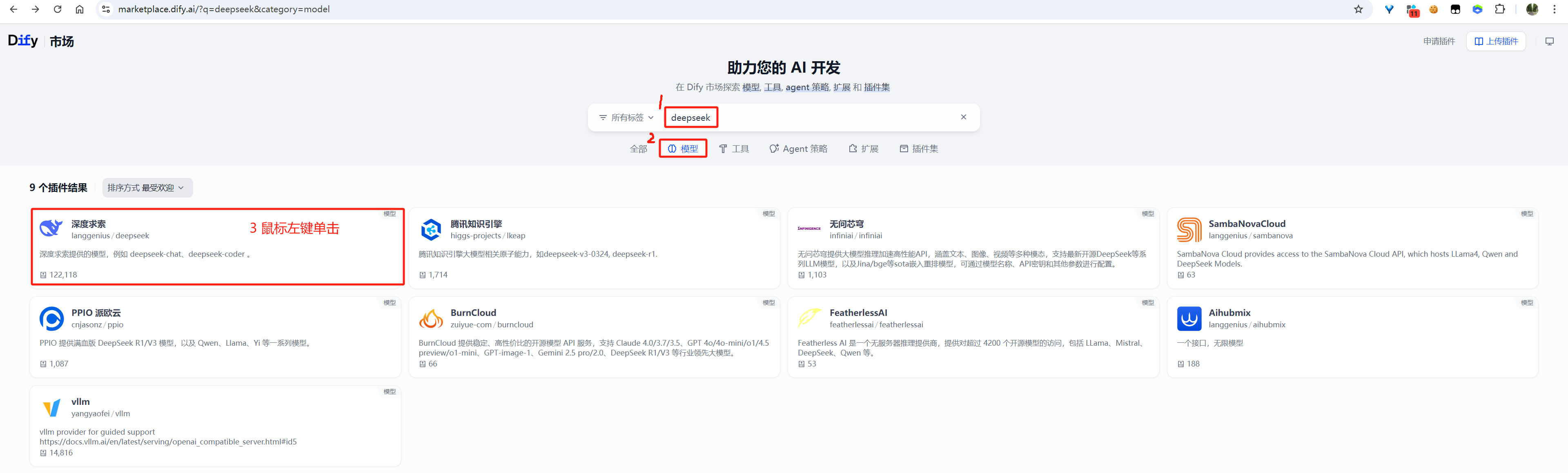
以下尝试以在线方式安装国产的“深度求索”模型供应商。
image-20250603150347954
2.1.2
以离线插件方式安装模型供应商
在 Dify 1.4.1
版本中,模型供应商可以通过插件的方式安装。此处以“本地插件”的方式来相关模型供应商。
2.1.2.1
下载deepseek相关模型供应商插件
访问 Dify插件市场(https://marketplace.dify.ai/),搜索
deepseek 并下载 .difypkg 文件。
image-20250603153025291
image-20250603153037303
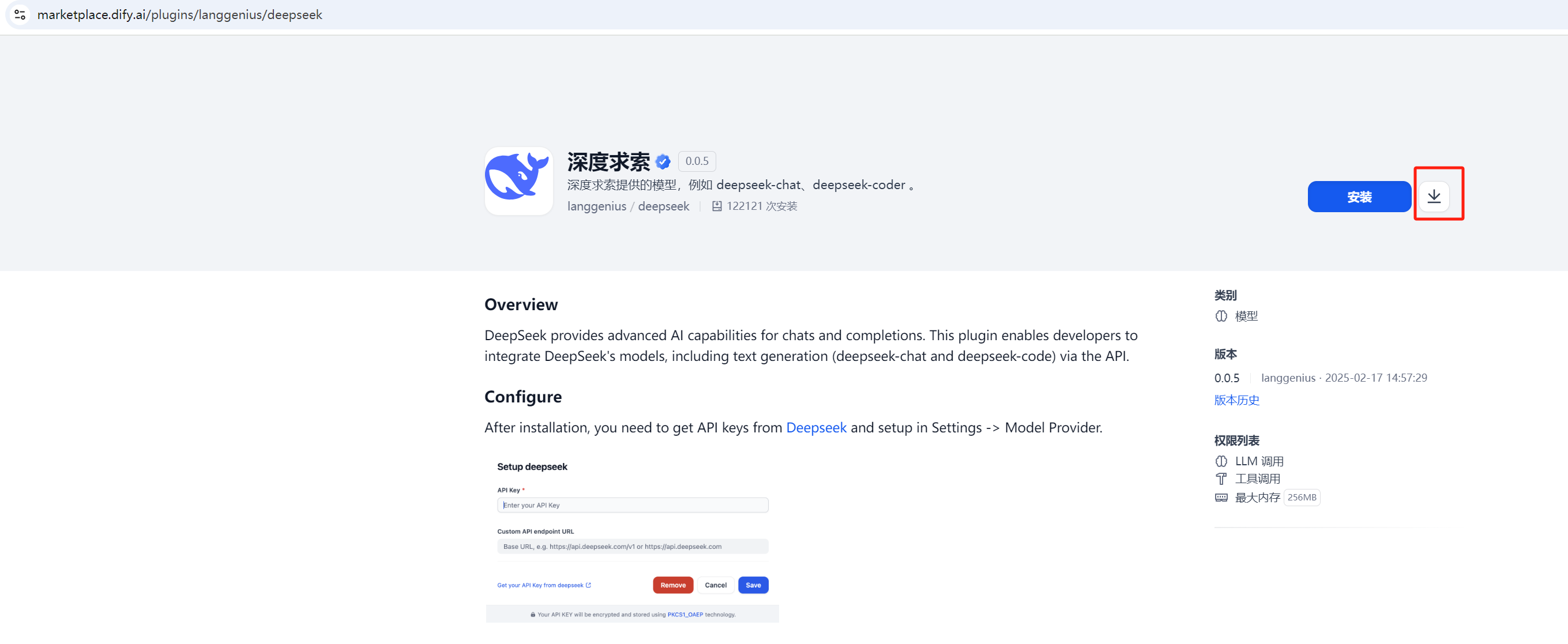
点击上图中的代表“下载”的图标后,正常时可以下载得到一个文件langgenius-deepseek_0.0.5.difypkg,保存在本地备用。
2.1.2.2 本地插件方式安装插件
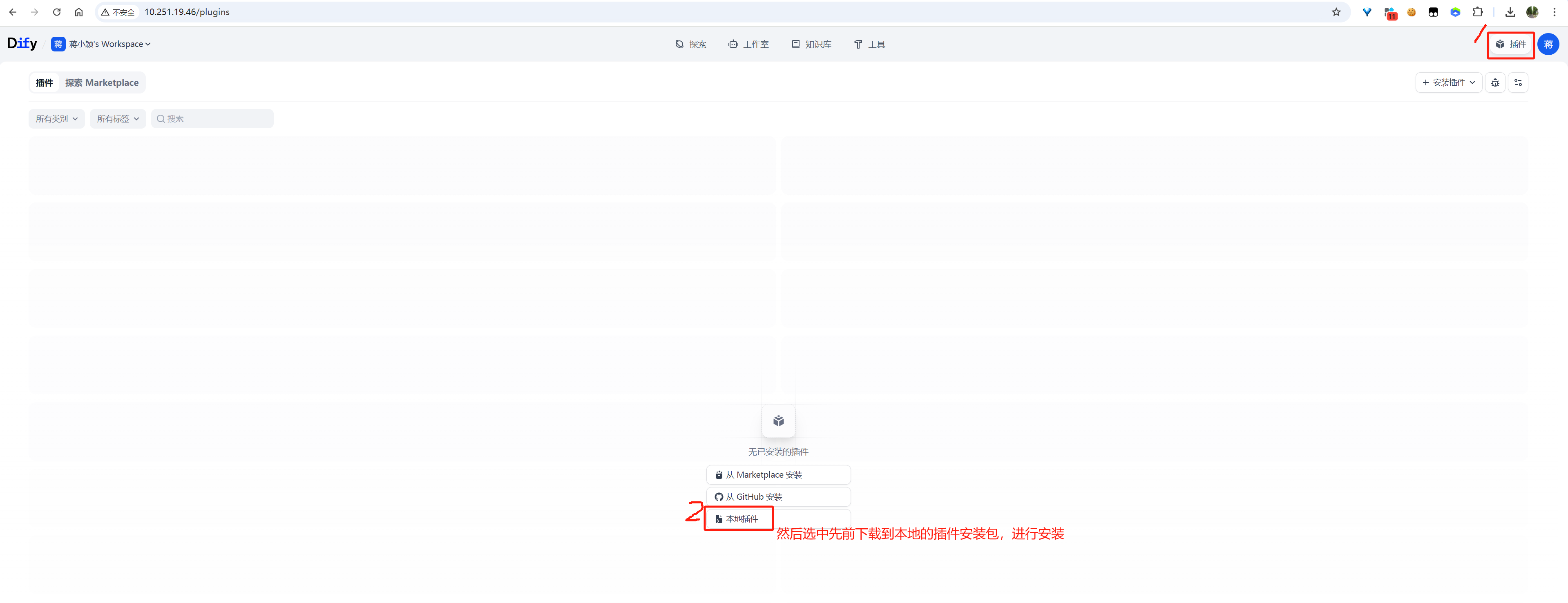
进入插件列表页面:
image-20250603153327091
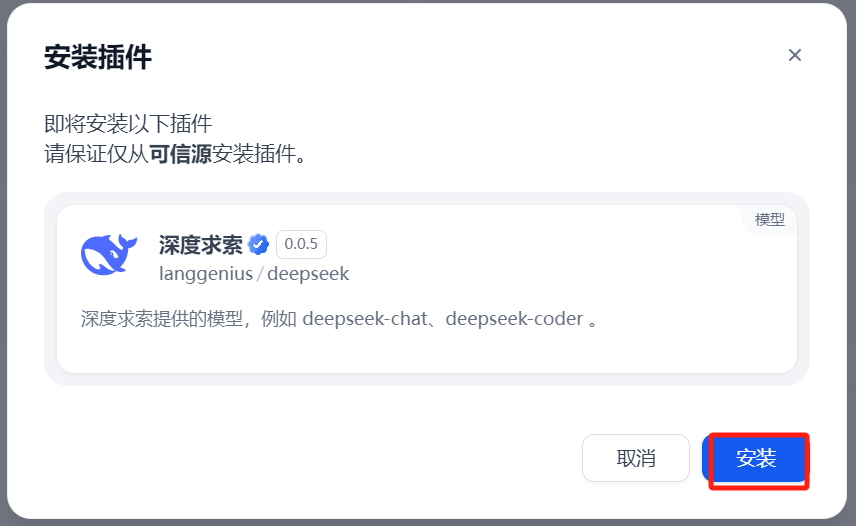
按照上图标注的文字,通过“本地插件”的方式安装插件(会提示用户选中本地保存的插件离线安装文件):
image-20250603153437474
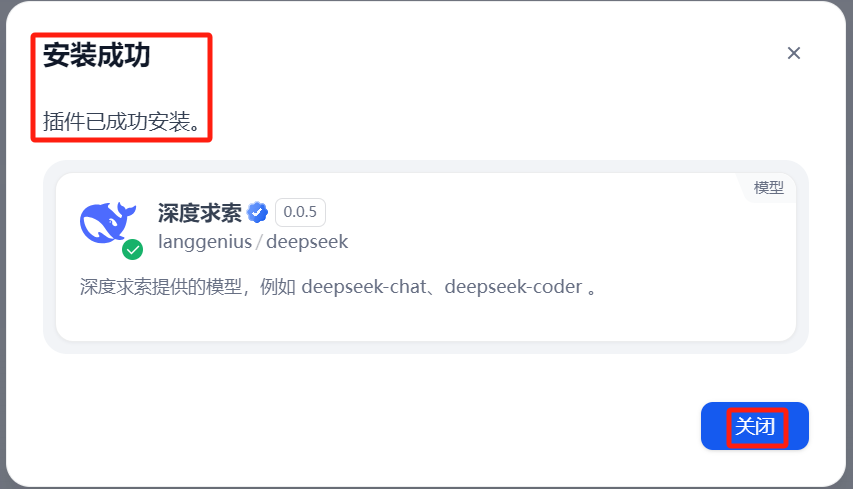
安装成功时,如下:
image-20250603153533147
同时在插件列表页面也可看到已经安装的插件:
image-20250603153704280
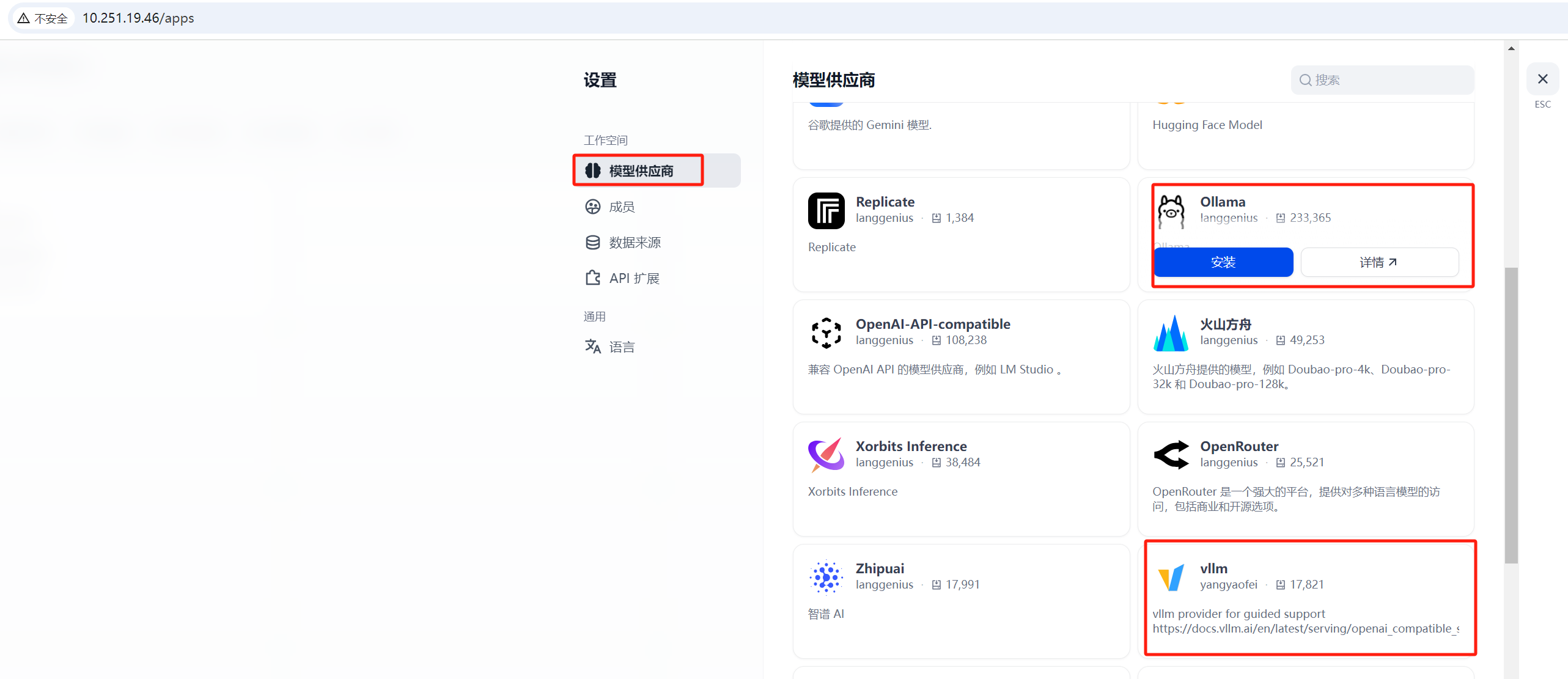
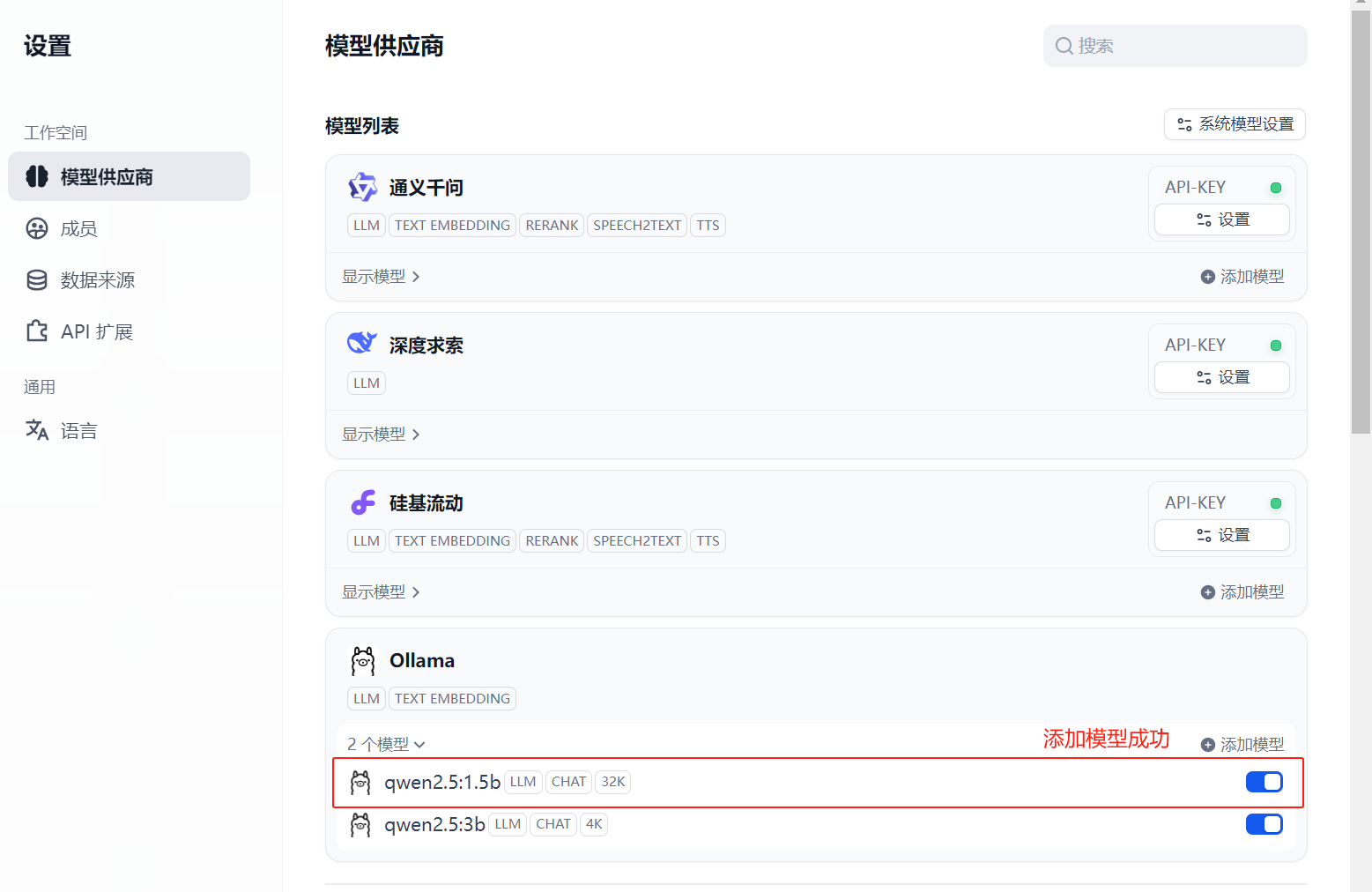
2.1.2.3 安装常用本地模型供应商
我们本地开发产品或使用时,一般都是自己在自己的服务器上部署开源LLM。部署开源LLM时使用的推理服务常用的有ollama与vllm。所以此处把这两个模型供应商都安装上。
image-20250617103203228
2.2 配置模型供应商
以下ollama与vllm都是部署在同一个服务器(其实是一个OpenStack虚拟机),dify1.4.1也部署在此服务器上。此服务器的内网IP:
10.11.15.190,浮动IP: 10.251.19.46 。
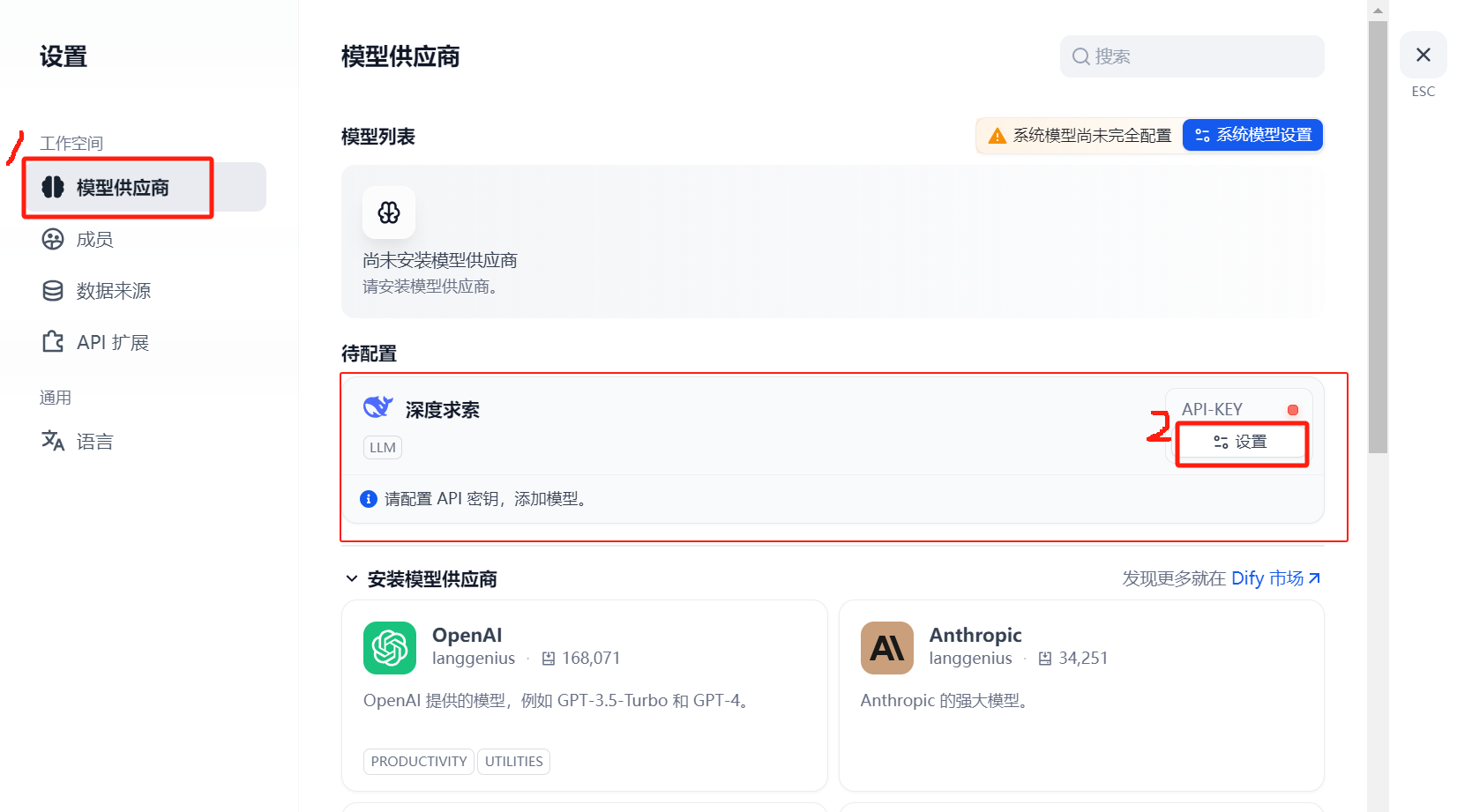
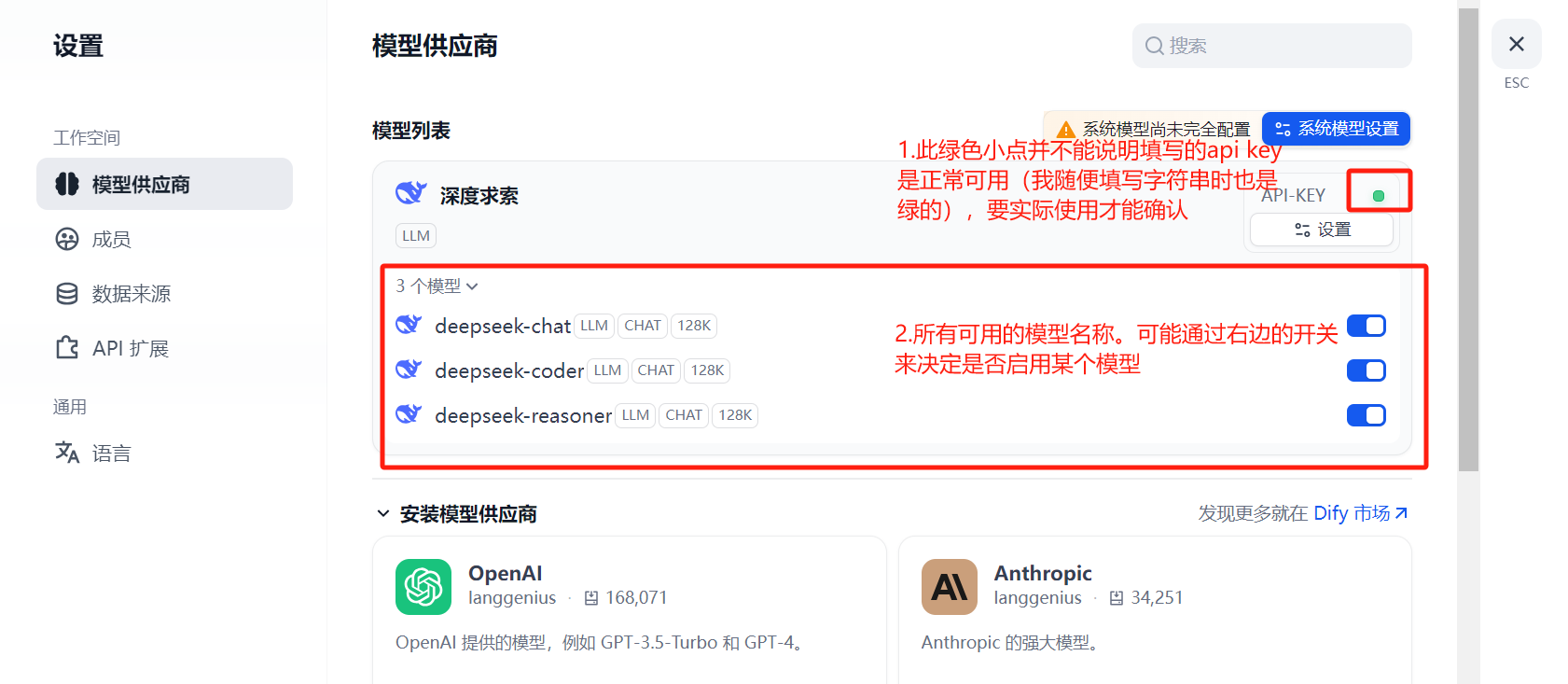
2.2.1 配置深度求索模型供应商
image-20250603160952200
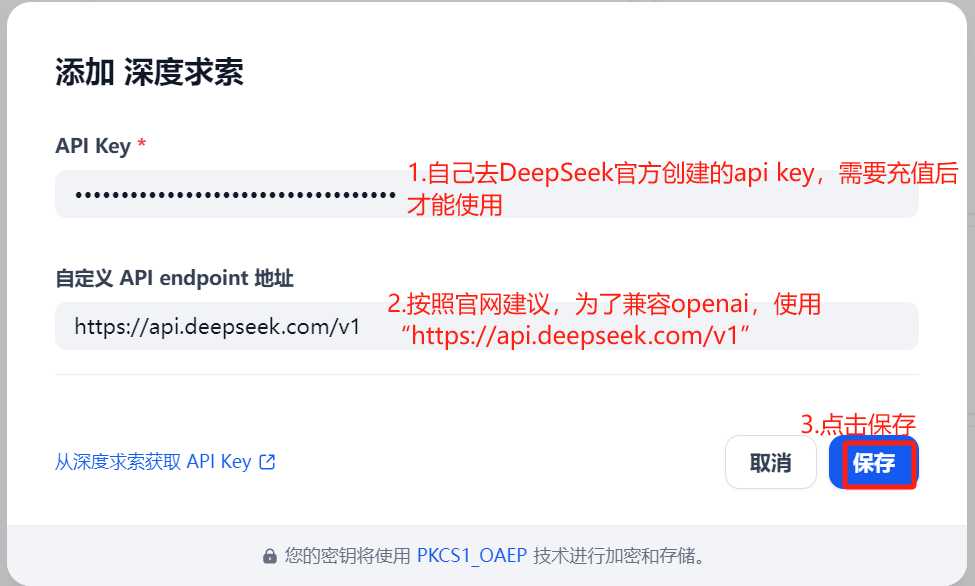
填写api key:
image-20250603161405917
查看模型列表:
image-20250603161916158
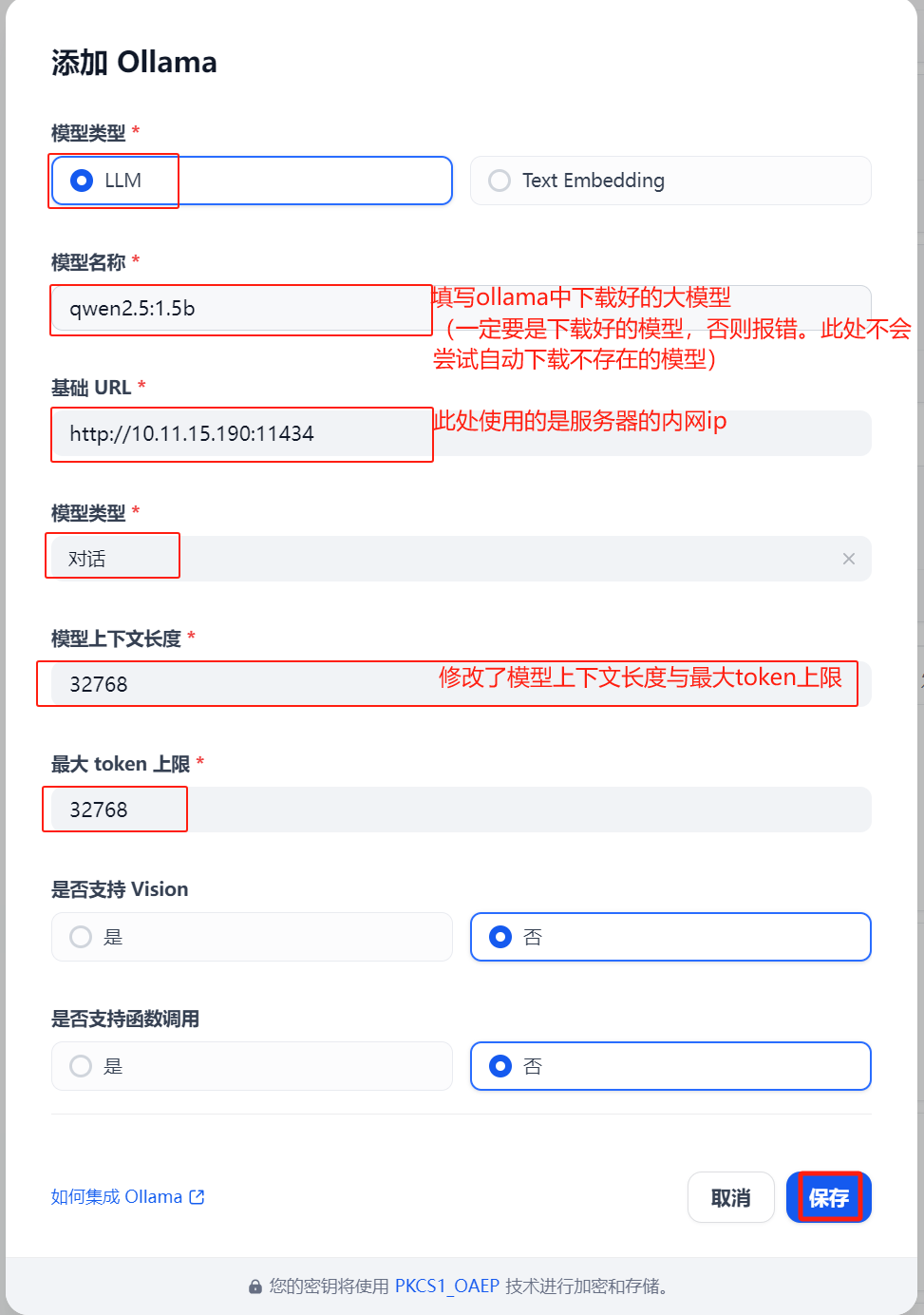
2.2.2 配置ollama模型供应商
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # systemd管理ollama服务 # ollama服务监听端口是默认的11434,可从任意服务器访问 # 查看ollama当前管理的大模型
image-20250617105901534
1 2 3 4 5 6 7 8 9 10 11 12 # 创建新目录,假设/mnt/ 是一个新磁盘分区挂载的目录 # /usr/share/ollama/.ollama/models 是ollama存储模型文件的默认目录 # 在[Service]下面添加如下内容:Environment="OLLAMA_MODELS=/mnt/ollama/.ollama/models"
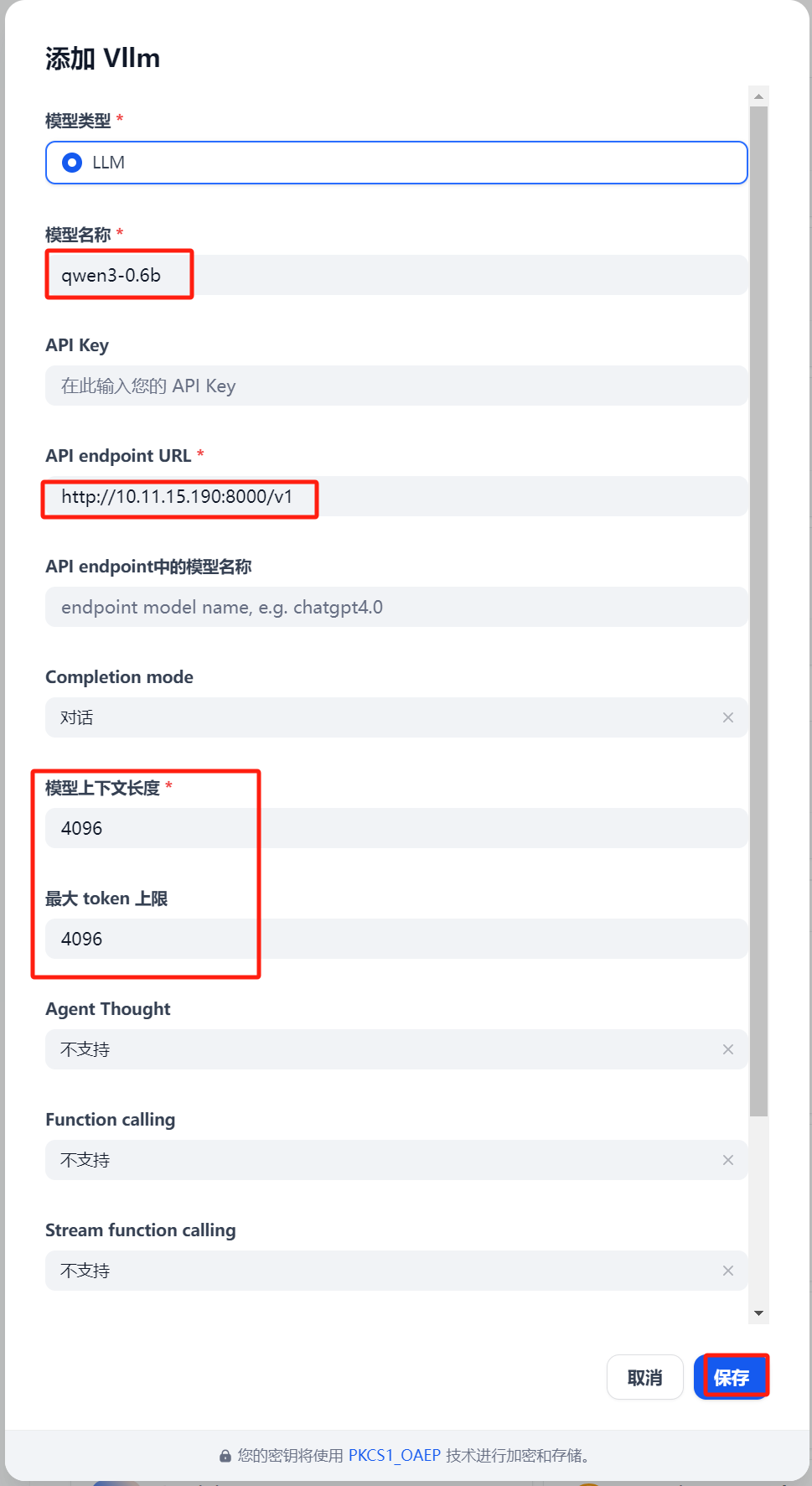
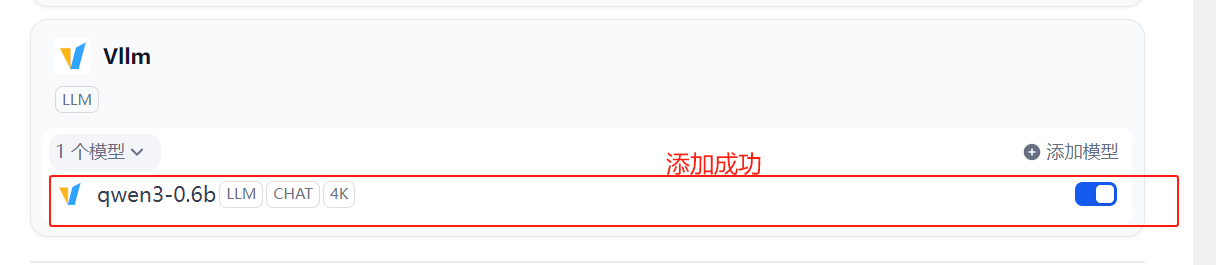
2.2.3 配置vllm模型供应商
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 以容器方式启动vllm进程 # vLLM 当前一次仅支持加载并运行一个大模型。如果要支持多个模型,可以运行多个 Docker 容器,每个容器加载不同模型,监听不同端口 # 查看所有模型 # 模型名: qwen3-0.6b # vllm服务base url: http://10.11.15.190:8000/v1
image-20250617175639704
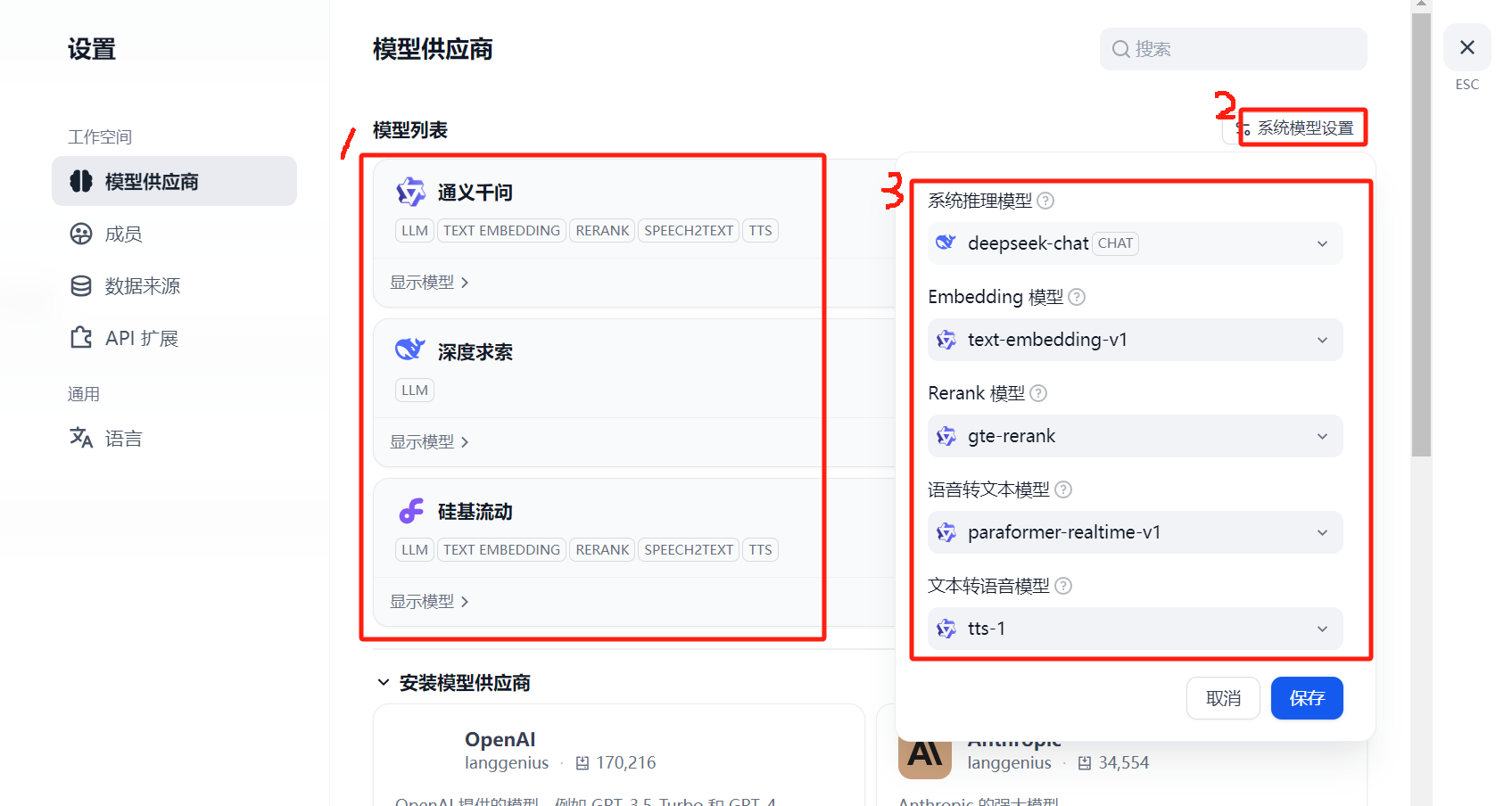
2.3 系统模型设置
由于DeepSeek官方只提供了可用于”系统推理模型“的LLM,其他模型如Embedding模型、Rerank模型等,可以通过安装通义千问插件并添加其api
key以使用。以下我一共安装与配置了3个插件:深度求索、通义千问与硅基流动。
image-20250604171434390
如果是自己开发与学习,建议安装、配置好ollama或vllm模型供应商,然后在系统模型设置中优先使用ollama或vllm中的模型