机器学习入门-06-支持向量机
第6章 支持向量机
6.1 间隔与支持向量
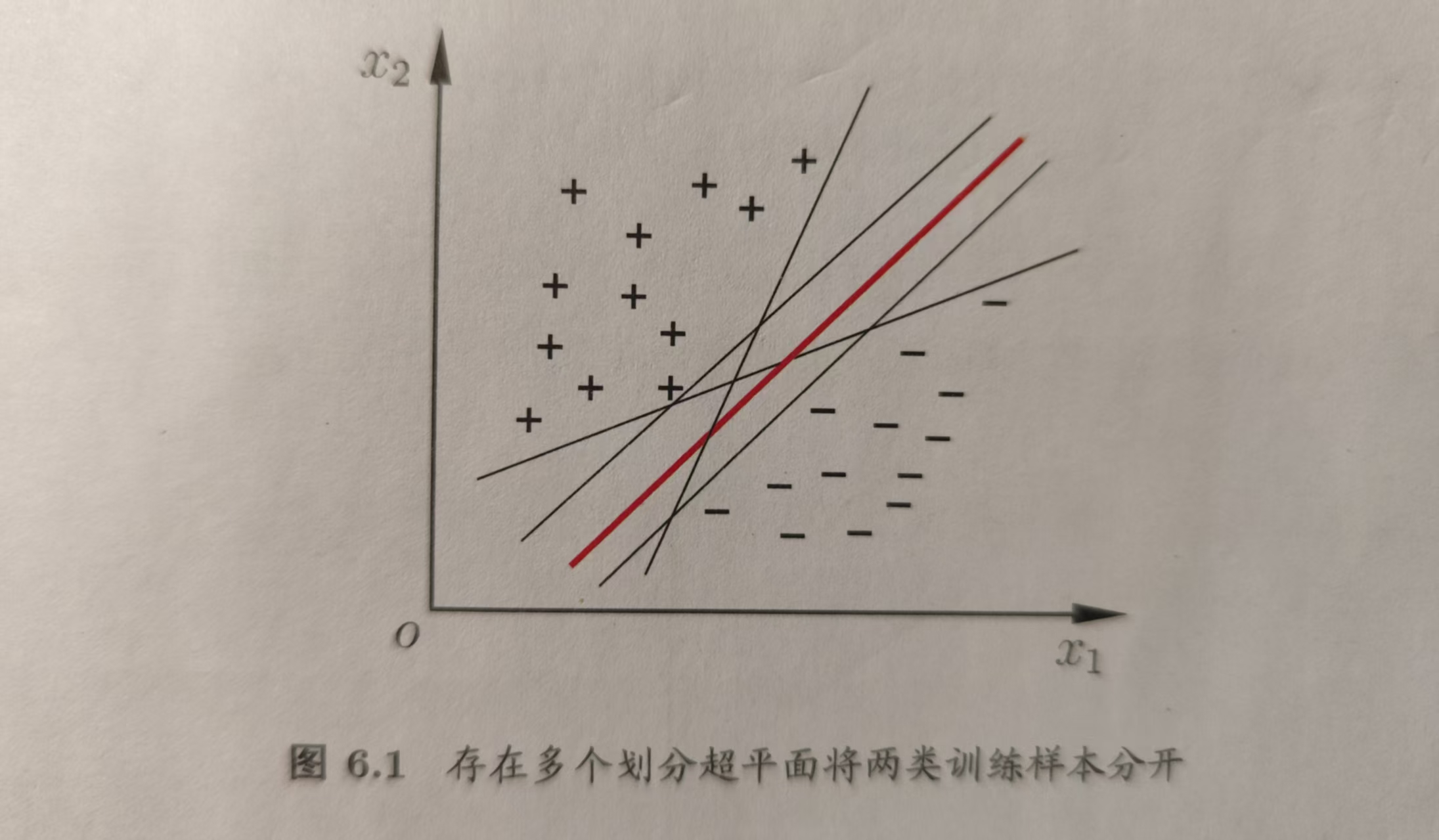
给定训练样本集D={(x1, y1), (x2, y2), ..., (xn, yn)}, yi∈{-1, +1},分类学习就是要基于训练样本集D在样本空间中找到一个划分超平面,将不同类别的样本分开。但在实际划分时,这样划分超平面可能是会很多个,我们应该在这些可能存在的多个划分超平面中找到一个“最优”的,那如何找到它?
这个最优的划分超平面应该具有如下特征:它位于两类训练样本的“正中间”,此时它对训练样本的局部扰动(比如训练集的局限性与噪声)的容忍性最好。此外训练集之外的样本如测试集与未知的其他实际数据,可能比我们目前知道的训练集更接近两个类的分界线即划分超平面,如果我们找到了正中间的那个划分超平面,那么这些新的数据仍可以被正确分类,就是说正中间的划分超平面受到的影响最小,它产生的分类结果是最具鲁棒性的、对未见的泛化能力最强。
这个最中间的划分超平面就是下图中这条红色的直线所代表的平面。
样本空间内,划分超平面可通过一个线性方程来描述: \[ \mathbf{ω}^T\mathbf{x}+b =0 \\ \tag{6.1} \]
\[ \begin{aligned} & 其中\mathbf{ω}=(ω_1, ω_2, ..., ω_d)是法向量,它决定了超平面的方向,\\ & b是位移项,它决定了超平面与原点之间的距离。 \\ & 显然划分超平面可以被法向量\mathbf{ω}与位移项b确定下来。\\ & 我们可以将法向量\mathbf{ω}与位移项b确定的超平面记为(\mathbf{ω}, b),此时样本空间中任意点\mathbf{x}到此超平面的距离为:\\ \end{aligned} \]
\[ r = \frac{|\mathbf{ω}^T\mathbf{x}+b|}{||\mathbf{ω}||} \\ \tag{6.2} \]
$$ \[\begin{aligned} & 假设超平面分类正确,即对于(\mathbf{x}_i, y_i)∈D,\\ & 若y_i=+1,则\mathbf{ω}^T\mathbf{x}+b >0; \\ & 若y_i=-1,则\mathbf{ω}^T\mathbf{x}+b <0; \\ \\ & 此时若令 \\ & \begin{cases} & \mathbf{ω}^T\mathbf{x}+b ≥+1, \quad y_i=+1 \quad\quad\quad (6.3式)\\[2ex] & \mathbf{ω}^T\mathbf{x}+b ≤-1, \quad y_i=-1 \\[2ex] \end{cases} \end{aligned}\]$$
从下图可以看出,距离超平面最近的几个样本使式6.3 的等号成,它们被入称为“支持向量”。
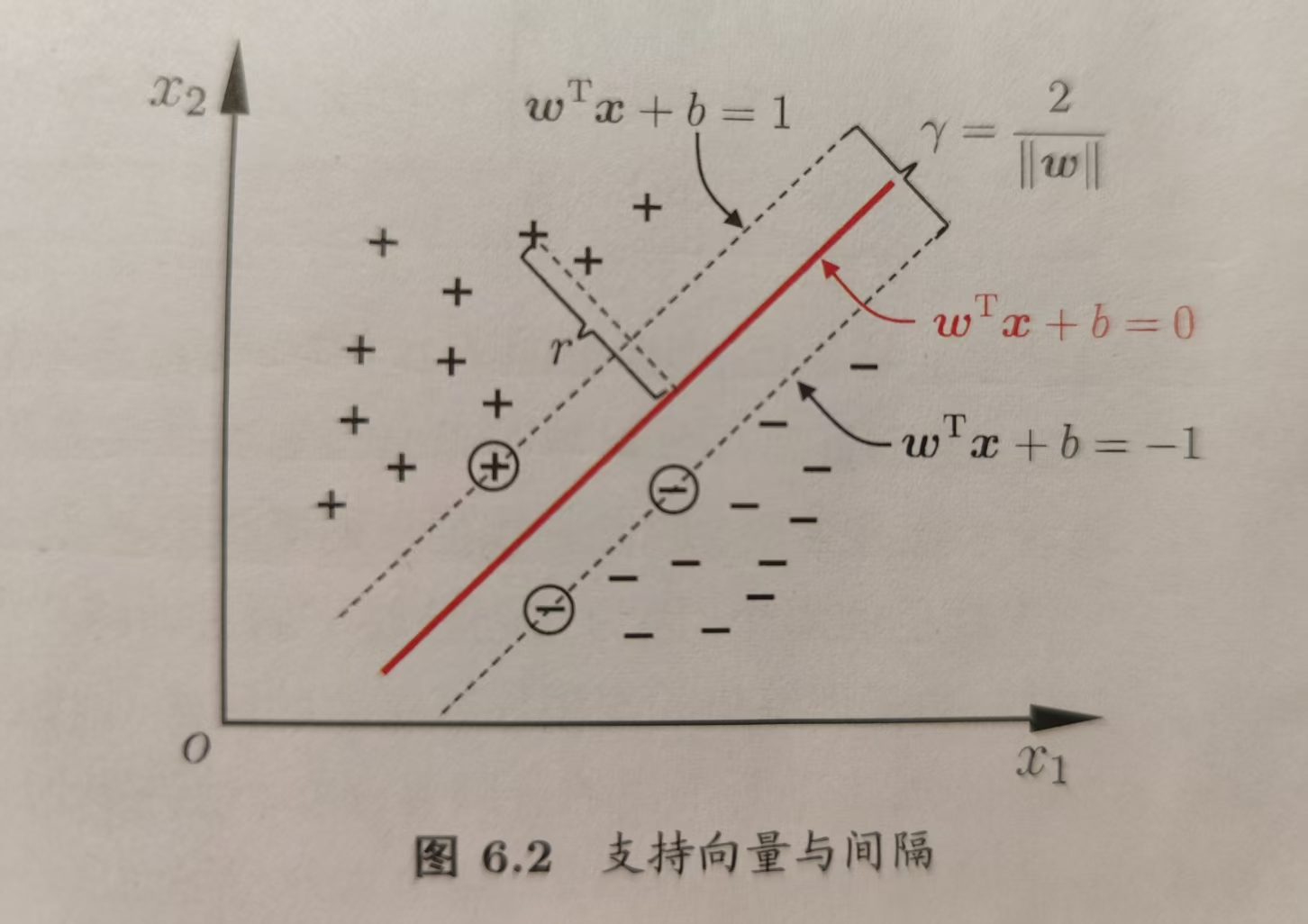
两个异类支持向量到划分超平面的距离之和被称为“间隔”,记为如下: \[ γ = \frac{2}{||\mathbf{ω}||} \\ \tag{6.4} 显然两个异类支持向量到超平面的距离都是\frac{1}{||\mathbf{ω}||} \] 我们的目标是找到具有“最大间隔”的超平面,也就是要找到满足(6.3式)中的约束参数ω与b,使得γ最大,即 \[ \begin{aligned} \underset{\mathbf{ω},b}{\text{max}}\;\frac{2}{||\mathbf{ω}||} \quad\quad\quad\quad\quad(6.5)\\ s.t.\;y_i(\mathbf{ω}^T\mathbf{x}+b)≥1, \quad i=1,2,...,m \end{aligned} \] 为了最大间隔,需要最大化||ω||-1 ,这等价于最小化||ω||。不妨将(6.5式)重写成如下: \[ \begin{aligned} \underset{\mathbf{ω},b}{\text{min}}\;\frac{1}{2}||\mathbf{ω}||^2 \quad\quad\quad\quad\quad(6.6)\\ s.t. \; y_i(\mathbf{ω}^T\mathbf{x}+b)≥1, \quad i=1,2,...,m \\ \text{其中b通过隐式约束影响着ω的取值,所以上述函数其实是关于ω与b两个变量的函数。}\\ \text{如上公式就是支持向量机(Supported Vector Machine,简称SVM)的基本型。}\\ \end{aligned} \]
6.2 对偶问题
根据前面的描述,我们希望求解(6.6式),具体地说是求解其中的ω与b,来得到最大间隔划分超平面对应的模型: \[ f(\mathbf{x})=\mathbf{ω}^T\mathbf{x}+b \tag{6.7}\\ \] 对于(6.6式),利用拉格朗日乘子法(暂时不知道,有待学习)可得到其”对偶问题“。具体求解过程如下:

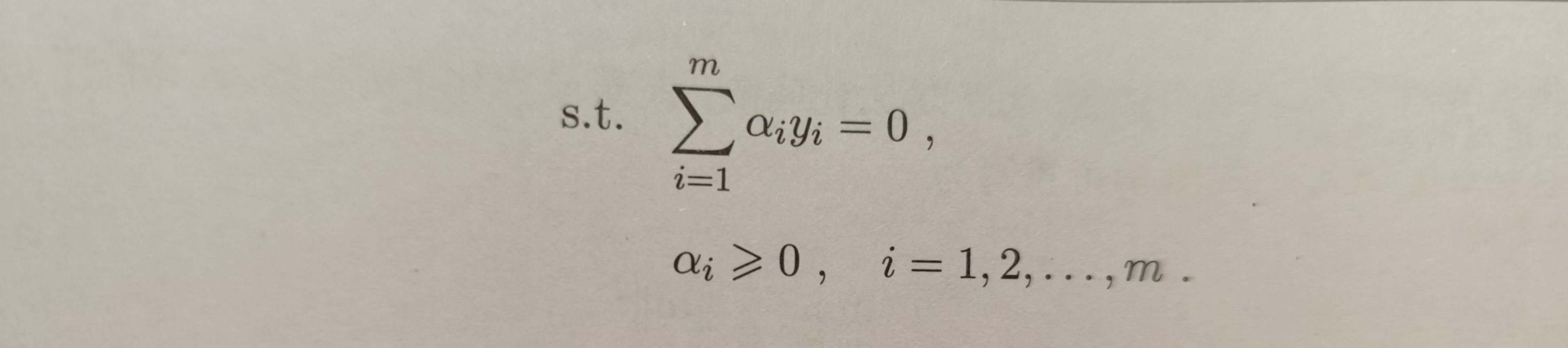 \[
\begin{aligned}
&
上面解出α后,求出\mathbf{ω}与b的值,即可得到超平面对应的模型f(\mathbf{x})=\mathbf{ω}^T\mathbf{x}+b
\\
&
又从(6.9式)可知:\mathbf{ω}=\sum_{i=1}^m{α_iy_i\mathbf{x_i}},代入上式可得:\\
&
f(\mathbf{x})=(\sum_{i=1}^m{α_iy_i\mathbf{x_i}})^T\mathbf{x}+b=(\sum_{i=1}^m{α_iy_i\mathbf{x_i}^T})\mathbf{x}+b \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(6.12)\\
\end{aligned}
\]
利用对偶问题解出拉格朗日乘子αi对应着样本(xi,
yi)。由于(6.6式)中存在约束条件,所以上述求解过程也需要满足KKT条件,详情如下:
\[
\begin{cases}
α_i≥0; \\
y_if(\mathbf{x_i})-1≥0;\\
α_i(y_if(\mathbf{x_i})-1)=0; \\ \tag{6.13}
\end{cases}\\
\]
\[
\begin{aligned}
&
上面解出α后,求出\mathbf{ω}与b的值,即可得到超平面对应的模型f(\mathbf{x})=\mathbf{ω}^T\mathbf{x}+b
\\
&
又从(6.9式)可知:\mathbf{ω}=\sum_{i=1}^m{α_iy_i\mathbf{x_i}},代入上式可得:\\
&
f(\mathbf{x})=(\sum_{i=1}^m{α_iy_i\mathbf{x_i}})^T\mathbf{x}+b=(\sum_{i=1}^m{α_iy_i\mathbf{x_i}^T})\mathbf{x}+b \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(6.12)\\
\end{aligned}
\]
利用对偶问题解出拉格朗日乘子αi对应着样本(xi,
yi)。由于(6.6式)中存在约束条件,所以上述求解过程也需要满足KKT条件,详情如下:
\[
\begin{cases}
α_i≥0; \\
y_if(\mathbf{x_i})-1≥0;\\
α_i(y_if(\mathbf{x_i})-1)=0; \\ \tag{6.13}
\end{cases}\\
\]
\[ \begin{aligned} & 对于任意训练样本(\mathbf{x_i}, y_i),总有α_i=0或y_if(\mathbf{x_i})=1\\ & 若α_i=0,则该样本不会出现在(6.12式)中的求和整体中,所以可以认为它对f(\mathbf{x})无影响;\\ & 若α_i>0,则必有y_if(\mathbf{x_i})=1,即此时样本(\mathbf{x_i}, y_i)落在最大间隔边界上,是一个支持向量。\\ & 以上告诉我们支持向量机的一个重要性质:最后的模型仅与支持向量有关,大部分训练样本无须保留(那些与α_i=0对应的样本) \end{aligned} \]
求解(6.11式)的具体过程暂未学习,待学习。
6.3 核函数
前面我们总是假设训练样本是线性可分的即存在一个划分超平面可将训练样本分为不同类别。但解决实际问题时,原始的样本空间内可能并不存在一个能正确划分两类样本的超平面,如下图所示的异或问题就不是线性可分的。
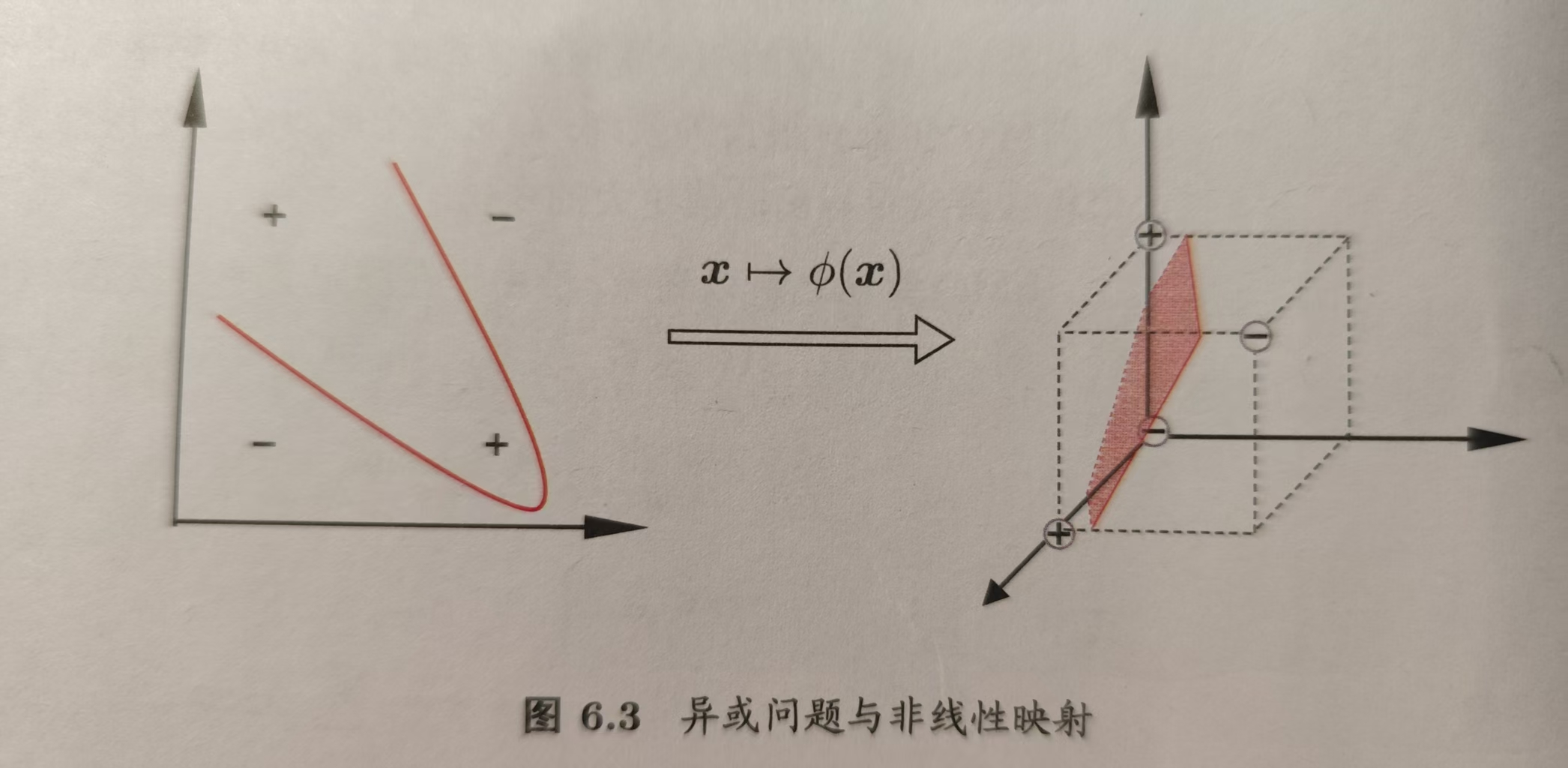
但我们可以将原始样本空间映射到一个高维的特征空间,这样就使得样本在生物空间内线性可分了。
如上图所示,若将原始的二维空间映射到一个合适的三维空间,就能找到一个便条的划分超平面。而且幸运地是(暂不知道如何证明):如果原始空间是有限维,即属性数有限,那么一定存在一个高维特征空间使样本可分。 \[ 令φ(\mathbf{x})表示将\mathbf{x}映射到线性可分的特征空间后的特征向量,此时在特征空间中划分超平面 所对应的模型可以表示为:\\ \]
\[ f(\mathbf{x})=\mathbf{ω}^Tφ(\mathbf{x})+b \tag{6.19}\\ \]
\[ \begin{aligned} 类似地,利用对偶问题的求解,可得:\\ f(\mathbf{x})=\mathbf{ω}^Tφ(\mathbf{x})+b \\ =(\sum_{i=1}^m{α_iy_iφ(\mathbf{x_i})^T}) φ(\mathbf{x})+b \\ =\sum_{i=1}^m{α_iy_iφ(\mathbf{x_i})^T} φ(\mathbf{x})+b \\ =\sum_{i=1}^m{α_iy_i}κ(x_i,x)+b \\ \end{aligned} \]
\[ f(\mathbf{x})==\sum_{i=1}^m{α_iy_i}κ(x,x_i)+b \tag{6.24} \]
其中函数κ(·,·)就是核函数,它是一个对称函数。
上式显示出模型优解可通过训练样本的核函数展开,这一展式亦称“支持向量展式”。 $$ \[\begin{aligned} & 定理6.1(核函数)\quad 令χ为输入空间,κ(·,·)是定义在χ×χ上的对称函数,则\\ & κ是核函数当且仅当对于任意数据D=({\mathbf{x_1}},\mathbf{x_2},...,\mathbf{x_m}),“核矩阵”Κ总是半正定的:\\ & Κ=\left[ \begin{matrix} κ(\mathbf{x_1},\mathbf{x_1}) & \cdots & κ(\mathbf{x_1},\mathbf{x_j}) & \cdots & κ(\mathbf{x_1},\mathbf{x_m}) \\ \vdots & \ddots & & \vdots \\ κ(\mathbf{x_i},\mathbf{x_1}) & \cdots & κ(\mathbf{x_i},\mathbf{x_j}) & \cdots & κ(\mathbf{x_i},\mathbf{x_m}) \\ \vdots & \ddots & & \vdots \\ κ(\mathbf{x_m},\mathbf{x_1}) & \cdots & κ(\mathbf{x_m},\mathbf{x_j}) & \cdots & κ(\mathbf{x_m},\mathbf{x_m}) \\ \end{matrix} \right] \end{aligned}\]$$
$$ \[\begin{aligned} & 正定矩阵:\\ & 对一个实对称矩阵A∈R^{n×n}是正定的,当且仅当其对于任意非零向量\mathbf{x}∈R^{n},满足\mathbf{x}^T\mathbf{A}\mathbf{x}>0恒成立 \\\\& 半正定矩阵:\\ & 对一个实对称矩阵A∈R^{n×n}是半正定的,当且仅当其对于任意非零向量\mathbf{x}∈R^{n},满足\mathbf{x}^T\mathbf{A}\mathbf{x}>=0恒成立。\\ & 矩阵A所有特征值 ≥ 0(至少一个为0) \\ & det(A)≥0 \\ & 矩阵A可能不可逆(秩亏损) \end{aligned}\]$$

$$
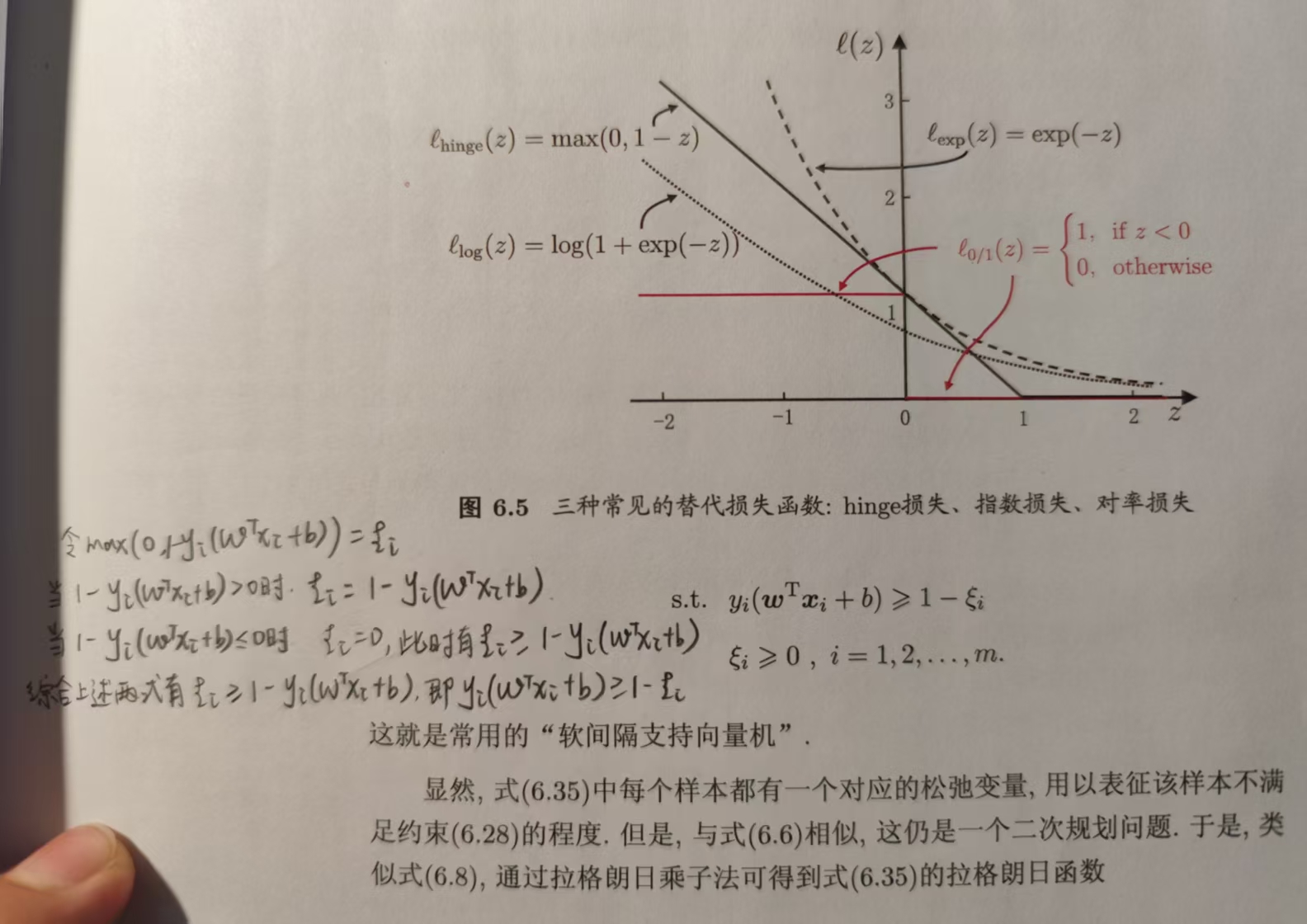
6.4 软间隔与正则化
在实际处理问题时,我们往往很难确定合适的核函数使得训练样本在特征空间中线性可分,或者就算找到某核函数使得训练样本在特征空间中线性可分,也难以确定这个在训练样本上线性可分的结果不是由于过拟合造成的。
所以缓解这一问题的办法是,允许支持向量机在少量样本上出错。为此引入软间隔的概念。

若支持向量机要求所有训练样本满足约束,即所有样本都划分正确,这称为硬间隔。而软间隔是允许某些样本不满足约束:
\[
y_i(\mathbf{ω}^T\mathbf{x_i}+b)≥1
\]