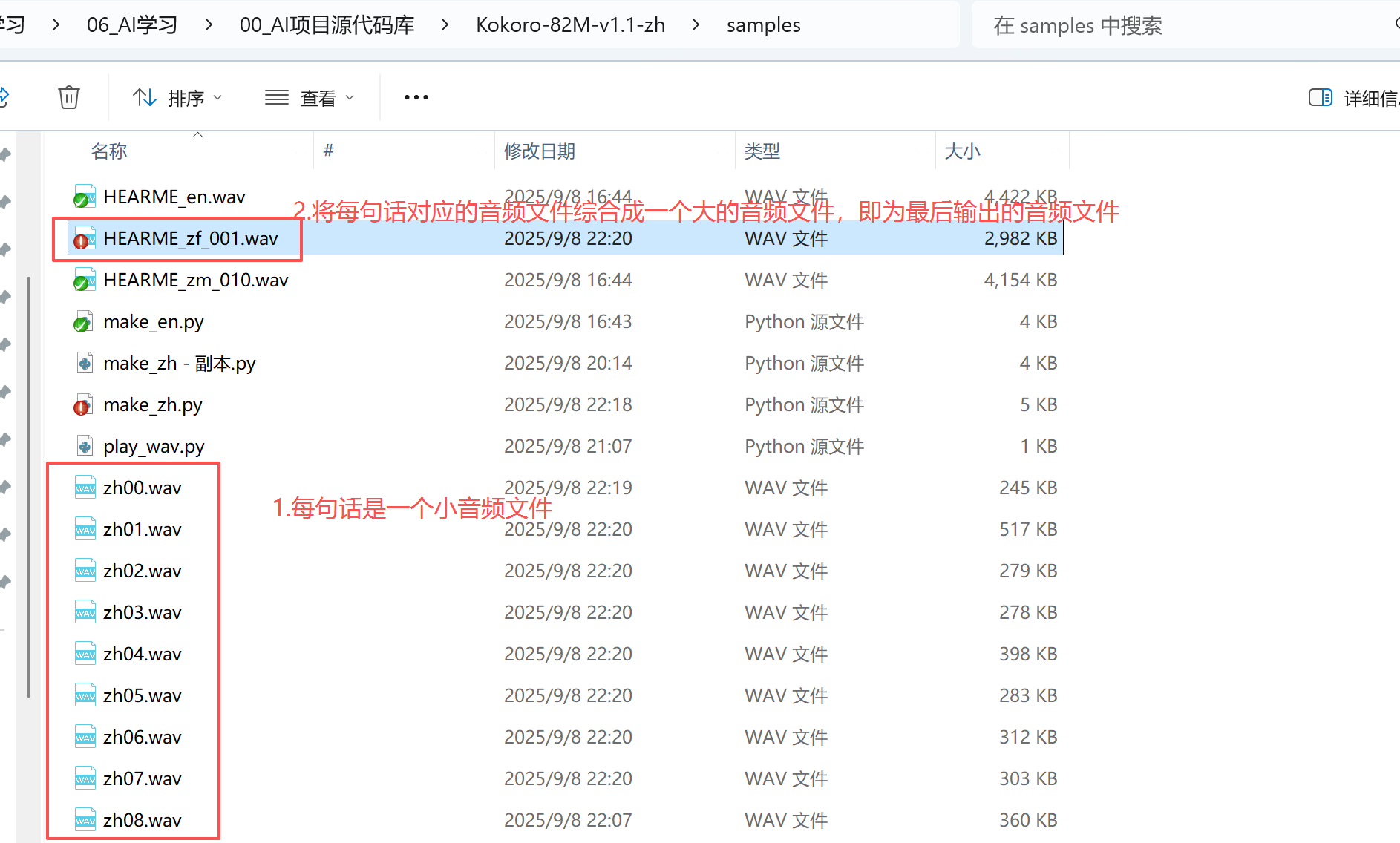
一、TTS 模型(音色与并发性能)
huggingface地址:https://huggingface.co/hexgrad/Kokoro-82M-v1.1-zh
,这是一个语音合成模型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 import osimport timefrom kokoro import KModel, KPipelinefrom pathlib import Pathimport numpy as npimport soundfile as sfimport torchimport tqdm'hexgrad/Kokoro-82M-v1.1-zh' 24000 5000 True 'cuda' if torch.cuda.is_available() else 'cpu' """ texts = [("ReAct全称是\"Reasoning and Acting\",可以翻译成“推理与行动”。", "它来自一篇于 2023 年 ICLR 会议上发表的会议论文https://arxiv.org/pdf/2210.03629 ", "ReAct相关的简介可在此查看https://react-lm.github.io/。"), ("在ReAct提出之前,大家都只是将推理与行动分开来进行研究", "比如推理方面就是提升LLM的推理能力,行动方面有给LLM增加FunctionCalling的能力等", "这篇论文首创性地提出将LLM的这二者结合起来协同使用。", "在解决问题的过程中,“reasoning traces”与“Actions”很多情况下是交错执行的", "前者帮助LLM进行推断、跟踪和更新行动方案,并处理异常情况;", "后者则使LLM能够与外部资源(如知识库或环境)进行交互,从而获取更多信息。")] """ class GenerateWav :'hexgrad/Kokoro-82M-v1.1-zh' 24000 5000 True 'cpu' 'a' , repo_id=REPO_ID, model=False ) @staticmethod def en_callable (text ):if text == 'Kokoro' :return 'kˈOkəɹO' elif text == 'Sol' :return 'sˈOl' return next (GenerateWav.en_pipeline(text)).phonemes @staticmethod def speed_callable (len_ps ):0.8 if len_ps <= 83 :1 elif len_ps < 183 :1 - (len_ps - 83 ) / 500 return speed * 1.1 print (f"正在使用的device:{device} " )eval ()'z' , repo_id=REPO_ID, model=model, en_callable=en_callable) @staticmethod def genetate_wav (texts: list , VOICE: str , device: str = 'cpu' , test_type: str = 'tone' ):try :"01_tone" if test_type == 'tone' else "02_concurrency" "-" +str (time.time()).replace("." , "" )f'{subdir_} ' )True )if test_type == 'tone' else wav_dirfor paragraph in tqdm.tqdm(texts):for i, sentence in enumerate (paragraph):f'zh{len (wavs):02} .wav' )next (generator)if i == 0 and wavs and N_ZEROS > 0 :f'HEARME_{VOICE} .wav' )print (f"生成的音频文件路径:{final_wav} ,花费时间(只统计文本转音频耗时,模型加载之类的时间不统计):{end - start} " )return {"code" : 200 ,"msg" : "成功" ,"data" : None except Exception as execption:print (f"出异常了,异常详情为:{execption} " )return {"code" : 500 ,"msg" : "异常" ,"data" : None def main (texts, voice, device, test_type ):return GenerateWav.genetate_wav(texts, voice, device, test_type)
上述示例中,将近400个中英文字符,在我的笔记本电脑上运行时长大概110秒。
执行上述python脚本后,会在py文件的同级目录下生成一个文章文件HEARME_zm_010.wav,这个文件就是所有文字对应的语音。其中文字内容是通过上述py脚本中的texts变量定义的,它是一个列表,列表中的元素类型是元组,每个元组代表一段文字内容;每个元组(每个段)包含多句,每句是元组中的一个元素。
image-20250908233511928
本章节以下数据都是在 10.8.36.12 物理服务器(安装有一个3090
GPU)上测得。
测试不同音色
在项目的voices目录有100个左右不同音色,尽量进行测试。
音色名称
性别
备注
af_maple
女
美国女性
af_sol
女
另一位美国女性
bf_vale
女
年长的英国女性
zf_xxx
中文-女声
zf_022 个人感觉比较好,声音温柔、专业、年轻
zm_yyy
中文-男声
zm_010 个人感觉比较好,声音稍有磁性、专业、年轻
测试并发生成音频
10字左右
1 2 3 4 5 6 7 8 9 10 11 12 texts_list = ["DNA是英文deoxyribonucleic acid的简写。" ,)],"RNA是英文ribonucleic acid的简写。" ,)],"MRI是英文magnetic resonance imaging的简写。" ,)],"CT是英文computed tomography的简写。" ,)],"API是英文application programming interface的简写。" ,)],"CPU是英文central processing unit的简写。" ,)],"GPU是英文graphics processing unit的简写。" ,)],"RAM是英文random access memory的简写。" ,)],"HTTP是英文hypertext transfer protocol的简写。" ,)],"SQL是英文structured query language的简写。" ,)],
使用CPU时
单线程处理,将10字左右内容转换成音频:0.57s~0.70s
使用GPU时
多线程并发处理,每个线程将10字左右内容转换成音频:
10个线程并发时,每个线程耗时约 0.659s~0.730s
20个线程并发时,每个线程耗时约 0.997s~1.805s
30个线程并发时,每个线程耗时约 1.700s~3.367s
启动2个服务
每个服务分别响应10个线程,每个线程耗时约 1.082s~1.166s
每个服务分别响应20个线程,每个线程耗时约 1.774s~2.556s
启动3个服务
每个服务分别响应10个线程,每个线程耗时约 1.281s~1.732s
20字左右
1 2 3 4 5 6 7 8 9 10 11 12 texts_list = ["EMR" , "电子病历系统,用于管理和共享患者信息,Electronic Medical Record 。" ,)],"EHR" , "电子健康档案,Electronic Health Record, 涵盖患者全面健康数据。" ,)],"ICU" , "Intensive Care Unit, 重症监护病房,为危重病人提供密切监护。" ,)],"CT" , "Computed Tomography, 计算机断层扫描技术,用于医学影像检查。" ,)],"MRI" , "磁共振成像技术,Magnetic Resonance Imaging, 提供软组织影像。" ,)],"AI" , "人工智能技术,Artificial Intelligence, 广泛应用于医学和IT。" ,)],"API" , "Application Programming Interface, 应用程序接口,促进系统交互。" ,)],"SQL" , "Structured Query Language, 结构化查询语言,用于数据库管理。" ,)],"GPU" , "图形处理单元,Graphics Processing Unit, 支持计算与AI训练。" ,)],"HTTP" , "Hypertext Transfer Protocol, 超文本传输协议,Web通信基础。" ,)],
使用CPU时
单线程处理,将20字左右内容转换成音频:1.06s~1.23s
使用GPU时
多线程并发处理,每个线程将20字左右内容转换成音频:
8个线程并发时,每个线程耗时约
0.666s~0.877s,如果9个线程就有可以超过1s了
10个线程并发时,每个线程耗时约 1.111s~1.397s
20个线程并发时,每个线程耗时约 2.843s~3.696s
30个线程并发时,每个线程耗时约 s~s
启动2个服务
每个服务分别响应10个线程,每个线程耗时约 1.517s~2.164s
每个服务分别响应20个线程,每个线程耗时约 3.345s~5.045s
启动3个服务
每个服务分别响应10个线程,每个线程耗时约 2.136s~3.076s
30字左右
1 2 3 4 5 6 7 8 9 10 11 12 texts_list = ["EMR" , "电子病历系统,Electronic Medical Record, 用于数字化记录和管理患者完整诊疗信息。" ,)],"EHR" , "Electronic Health Record, 电子健康档案,整合医疗机构数据提供患者跨机构共享健康记录。" ,)],"ICU" , "Intensive Care Unit, 重症监护病房,专为危重患者提供连续监护和救治的医疗场所。" ,)],"CT" , "计算机断层扫描技术,Computed Tomography, 利用X射线提供器官结构的横断面影像信息。" ,)],"MRI" , "Magnetic Resonance Imaging, 磁共振成像技术,利用磁场和射频信号获取精细软组织影像。" ,)],"AI" , "Artificial Intelligence, 人工智能,应用于图像识别自然语言处理及医学辅助诊断等领域。" ,)],"API" , "Application Programming Interface, 应用程序接口,提供系统间调用和数据交互的统一规范。" ,)],"SQL" , "结构化查询语言,Structured Query Language, 专门用于关系型数据库管理与复杂数据查询。" ,)],"GPU" , "Graphics Processing Unit, 图形处理单元,广泛用于并行计算图形渲染和深度学习模型训练。" ,)],"HTTP" , "超文本传输协议,Hypertext Transfer Protocol, 定义了浏览器与服务器之间数据传输方式。" ,)],
使用CPU时
单线程处理,将30字左右内容转换成音频:1.49s~1.70s
使用GPU时
多线程并发处理,每个线程将30字左右内容转换成音频:
10个线程并发时,每个线程耗时约 1.142s~1.492s
20个线程并发时,每个线程耗时约 2.837s~3.802s
30个线程并发时,每个线程耗时约 s~s
启动2个服务
每个服务分别响应10个线程,每个线程耗时约 1.483s~2.478s
每个服务分别响应20个线程,每个线程耗时约 3.434s~5.586s
启动3个服务
每个服务分别响应10个线程,每个线程耗时约 1.557s~3.048s
40字左右
1 2 3 4 5 6 7 8 9 10 11 12 13 texts_list = ["EMR" , "电子病历,数字化记录患者就诊信息,Electronic Medical Record, 实现医疗数据管理与共享的核心系统。" ,)],"EHR" , "Electronic Health Record, 电子健康档案,整合不同机构医疗数据,为患者提供连续全面的健康记录服务。" ,)],"ICU" , "Intensive Care Unit, 重症监护病房,配备先进设备和专科团队,为危重症患者提供全天候监护与治疗。" ,)],"CT" , "计算机断层扫描,利用X射线成像技术生成断层图像,Computed Tomography, 广泛用于疾病诊断和检查。" ,)],"MRI" , "Magnetic Resonance Imaging, 磁共振成像,利用磁场与射频信号成像,特别适用于软组织疾病的检测。" ,)],"AI" , "Artificial Intelligence, 人工智能,应用于医疗影像识别、自然语言处理及临床辅助决策等多个领域。" ,)],"API" , "应用程序接口,Application Programming Interface, 定义不同系统之间交互方式,实现功能调用与数据交换。" ,)],"SQL" , "Structured Query Language, 结构化查询语言,用于关系数据库的数据查询更新和管理的标准语言。" ,)],"GPU" , "图形处理单元,Graphics Processing Unit, 擅长并行计算,被广泛用于图像渲染和人工智能训练。" ,)],"HTTP" , "Hypertext Transfer Protocol, 超文本传输协议,规定浏览器与服务器之间传输超文本数据的标准方式。" ,)],
使用CPU时
单线程处理,将40字左右内容转换成音频:1.56s~1.93s
使用GPU时
多线程并发处理,每个线程将40字左右内容转换成音频:
10个线程并发时,每个线程耗时约 1.241s~1.639s
20个线程并发时,每个线程耗时约 3.052s~4.179s
30个线程并发时,每个线程耗时约 s~s
启动2个服务
每个服务分别响应10个线程,每个线程耗时约 1.522s~2.682s
每个服务分别响应20个线程,每个线程耗时约 3.682s~6.107s
启动3个服务
每个服务分别响应10个线程,每个线程耗时约 1.902s~3.358s
总结:
50字左右(全中文)
Kokoro-82M-v1.1-zh将50字左右的文字转换成音频。多线程情况下,不同线程可以使用相同的文字内容也可能是不同的文字内容,但字数差不多。
单句文本转语音时注意
1 2 3 4 "西安市" , "陕西省会,历史文化古都,科教实力雄厚,航空航天、电子信息等产业在西部地位突出。" )] "西安市,陕西省会,历史文化古都,科教实力雄厚,航空航天、电子信息等产业在西部地位突出。" ,) ]
总结:
注意当待文本内容只有一名话时,要使用写法2,写法1是错误的。写法1虽然也是定义一个列表,但是列表中的元素其实是一个字符串,而不是我们期望的元组,这样写法的结果是:程序将每个字转换为一个小音频文件,最终将形成43个小音频文件(上述一共包含43个中文字符),最后程序再将这43个音频文件拼接成一个总的音频文件,虽然内容是对的,但因为处理程序认为每个小音频文件就是一句话,拼接时将在这些小音频文件中间插入一个停顿间隔(间隔是动态调整的),导致拼接后得到的音频听起来是断断续续的,无法正常使用
CPU下分句效率及优化策略
CPU情况下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 "Kokoro 是一系列体积虽小但功能强大的 TTS 模型。" ,"该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。" ,"中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。" ,"另外,一些众包合成英语数据也进入了训练组合:" ,"1小时的 Maple,美国女性。" ,"1小时的 Sol,另一位美国女性。" ,"和1小时的 Vale,一位年长的英国女性。" ,"由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。" ,"除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。" ,"目标是推动模型系列的发展,并最终恢复一些被遗留的声音。" ,"美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" ,"由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。" ,"该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。" ,"如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。" ,"该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。" ,"中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。" ,"另外,一些众包合成英语数据也进入了训练组合:" ,"1小时的 Maple,美国女性。" ,"1小时的 Sol,另一位美国女性。" ,"和1小时的 Vale,一位年长的英国女性。" ,"由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。" ,"除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。" ,"目标是推动模型系列的发展,并最终恢复一些被遗留的声音。" ,"美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" ,"由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。" ,"该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。" ,"如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。另外,一些众包合成英语数据也进入了训练组合:1小时的 Maple,美国女性。1小时的 Sol,另一位美国女性。和1小时的 Vale,一位年长的英国女性。由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。目标是推动模型系列的发展,并最终恢复一些被遗留的声音。美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。另外,一些众包合成英语数据也进入了训练组合:1小时的 Maple,美国女性。1小时的 Sol,另一位美国女性。" , "和1小时的 Vale,一位年长的英国女性。由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。目标是推动模型系列的发展,并最终恢复一些被遗留的声音。美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" , "由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,
总结:
(1)Kokoro-82M-v1.1-zh一次性能处理的文本上下文窗口比较小,测试时发现其一次性能够处理的中英文字符上限大概在150字左右。
(2)如果一个段落包含多个句子,最好将它们拆成元组的不同元素分别存放,这样能够获得更好的句间停顿检验。
注:所有待处理文本内容都被填充在一个列表中,列表中的元素类型都是元组。每一个元组代表一个段落,每个段落可能有多句话,每句话就是元组的一个元素,根据上述测试结果,我们应该尽量考虑语义连贯的同时,将一个段落拆分成多个短句(常规就用中文的句号、感叹、疑问号等作为分句的标识),每个短句对应的字符串是元组的一个元素。
(3)合理的分句,而不是将一大串文本内容当成一个句子处理,能够稍微提高点转换效率(428个字符,其中有效中英文字符大概400个左右,合理分句,能将文本转语音耗时减少0.2s左右(12.3s—>12.1s))。
GPU下分句效率及优化策略
GPU情况下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 "Kokoro 是一系列体积虽小但功能强大的 TTS 模型。" ,"该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。" ,"中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。" ,"另外,一些众包合成英语数据也进入了训练组合:" ,"1小时的 Maple,美国女性。" ,"1小时的 Sol,另一位美国女性。" ,"和1小时的 Vale,一位年长的英国女性。" ,"由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。" ,"除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。" ,"目标是推动模型系列的发展,并最终恢复一些被遗留的声音。" ,"美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" ,"由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。" ,"该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。" ,"如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。" ,"该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。" ,"中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。" ,"另外,一些众包合成英语数据也进入了训练组合:" ,"1小时的 Maple,美国女性。" ,"1小时的 Sol,另一位美国女性。" ,"和1小时的 Vale,一位年长的英国女性。" ,"由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。" ,"除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。" ,"目标是推动模型系列的发展,并最终恢复一些被遗留的声音。" ,"美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" ,"由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。" ,"该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。" ,"如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。另外,一些众包合成英语数据也进入了训练组合:1小时的 Maple,美国女性。1小时的 Sol,另一位美国女性。和1小时的 Vale,一位年长的英国女性。由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。目标是推动模型系列的发展,并最终恢复一些被遗留的声音。美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,"Kokoro 是一系列体积虽小但功能强大的 TTS 模型。该模型是经过短期训练的结果,从专业数据集中添加了100名中文使用者。中文数据由专业数据集公司「龙猫数据」免费且无偿地提供给我们。感谢你们让这个模型成为可能。另外,一些众包合成英语数据也进入了训练组合:1小时的 Maple,美国女性。1小时的 Sol,另一位美国女性。" , "和1小时的 Vale,一位年长的英国女性。由于该模型删除了许多声音,因此它并不是对其前身的严格升级,但它提前发布以收集有关新声音和标记化的反馈。除了中文数据集和3小时的英语之外,其余数据都留在本次训练中。目标是推动模型系列的发展,并最终恢复一些被遗留的声音。美国版权局目前的指导表明,合成数据通常不符合版权保护的资格。" , "由于这些合成数据是众包的,因此模型训练师不受任何服务条款的约束。该 Apache 许可模式也符合 OpenAI 所宣称的广泛传播 AI 优势的使命。如果您愿意帮助进一步完成这一使命,请考虑为此贡献许可的音频数据。" ,
总结:
(1)跟CPU时类似,Kokoro-82M-v1.1-zh一次性能处理的文本上下文窗口比较小,测试时发现其一次性能够处理的中英文字符上限大概在150字左右。
(2)跟CPU时类似,如果一个段落包含多个句子,最好将它们拆成元组的不同元素分别存放,这样能够获得更好的句间停顿检验。
注:所有待处理文本内容都被填充在一个列表中,列表中的元素类型都是元组。每一个元组代表一个段落,每个段落可能有多句话,每句话就是元组的一个元素,根据上述测试结果,我们应该尽量考虑语义连贯的同时,将一个段落拆分成多个短句(常规就用中文的句号、感叹、疑问号等作为分句的标识),每个短句对应的字符串是元组的一个元素。
(3)合理的分句,将一大串文本内容当成一个句子处理(但不能超过Kokoro-82M-v1.1-zh处理窗口:大概只包含了175个字符,其中有效中英文字符是155个,其余是标点符号),能够较大提高转换效率(428个字符,其中有效中英文字符大概400个左右,合理分句,能将文本转语音耗时减少0.786s左右,耗时减少50%+)。----------此处使用GPU时跟使用CPU时,差距比较大
进一步测试
10、20、30、40个字左右,cpu只测试单线程,GPU情况下测试只多线程及其极限
在GPU情况下,可以增加服务数量,测试下服务器下支持极限,文本转语音耗时大致不超过1s
操作见:“测试并发生成音频”章节
二、语音合成MeloTTS(音色与并发性能)
github仓库地址:https://github.com/myshell-ai/MeloTTS
开源项目 MeloTTS 是一个高质量的 多语言文本转语音(Text-to-Speech,
TTS) 库,主要功能和特点如下:
项目概述:
MeloTTS 由 MyShell.ai 联合 MIT
与清华大学团队开发,是一个多语言支持的 TTS
系统,具有自然流畅的语音合成能力。
支持包括英语(多个口音)、西班牙语、法语、中文(支持中英混合)、日语、韩语在内的多种语言和口音。
它可以在 CPU 上实时推理使用,有较高的效率。当然也可以使用GPU
1 2 3 4 5 docker run -it --gpus all --name melotts -e HF_ENDPOINT="https://hf-mirror.com" -e http_proxy="http://10.13.15.34:7891" -e https_proxy="http://10.13.15.34:7891" -p 8888:8888 swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/sensejworld/melotts# 第一次转换文件为语音时时,容器内相关进程会自动下载 pytorch_model.bin 文件,保存位置应该是容器内的“/root/.cache/huggingface/hub/models--bert-base-multilingual-uncased/blobs/”目录下,保存文件并不是叫pytorch_model.bin,而是一个人眼无法识别的字符串名文件,文件大小为672M左右 # 此处我创建并运行此容器的服务器IP是 10.8.36.12
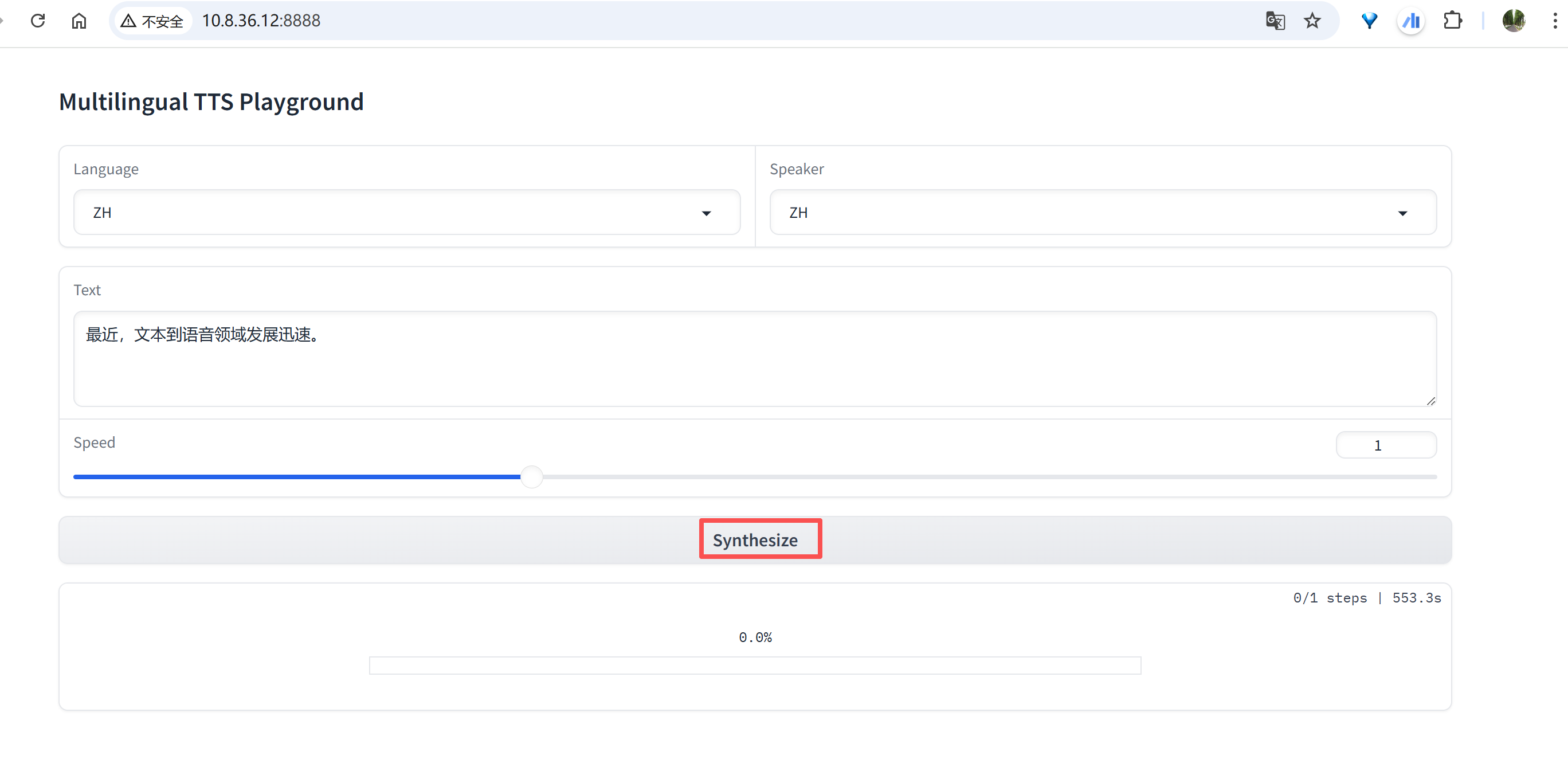
UI界面使用
然后在浏览器中访问“10.8.36.12:8888”可以看到如下界面,选定Language并设定Text文本框中的内容后,点击“Synthesize”按钮,启动文本转语音过程。
image-20250910142252059
三、语音识别SenseVoice(性能测试)
GitHub 项目 SenseVoice (来自 FunAudioLLM
组织)是一个功能强大的
多语种语音理解基础模型 ,专注于构建高性能、低延迟的语音理解服务。
项目介绍
SenseVoice 是一种 Speech Foundation
Model,具备以下核心功能 :
自动语音识别(ASR) :支持超过 50
种语言的高精度识别,训练语料超过 40 万小时,识别性能在中文、粤语上优于
Whisper 模型。GitHub Hugging
Face 语种识别(LID) :可以自动判断音频所使用的语言。GitHub 语音情感识别(SER) :能够识别语音中的情感,并在多个测试数据中表现超过当前最优情感识别模型。GitHub MarkTechPost 音频事件检测(AED) :具备识别背景音乐、掌声、笑声、哭声、咳嗽、打喷嚏等语音交互中的常见事件的能力。GitHub MarkTechPost 高效推理 :SenseVoice-Small
使用非自回归端到端结构,推理十分高效,处理 10 秒音频仅需约 70
毫秒,速度是 Whisper-Large 的 15 倍以上、Whisper-Small 的 5 倍以上。GitHub Hugging
Face 便于微调与服务部署 :提供微调脚本、ONNX/lbTorch
导出工具,并支持 Python、C++、Java、C#、HTML
等多种客户端语言的服务部署管道。
四、语音合成
fish-speech-1.5(性能测试)
GitHub 开源项目 Fish-Speech (位于
fishaudio/fish-speech)是一个先进的
开源多语言文本转语音(TTS)系统 。以下是其核心功能与特点:
Fish-Speech 项目简介
项目定位 :一个 SOTA(最先进)开源 TTS
系统 ,具备高质量合成能力,支持多语言和情感控制,专注于语音合成与语音克隆。GitHub 品牌演进 :该项目已升级并重命名为
OpenAudio ,推出了更先进的模型如
OpenAudio-S1、OpenAudio-S1-mini,于 Fish Audio Playground 和 Hugging
Face 平台上提供使用。