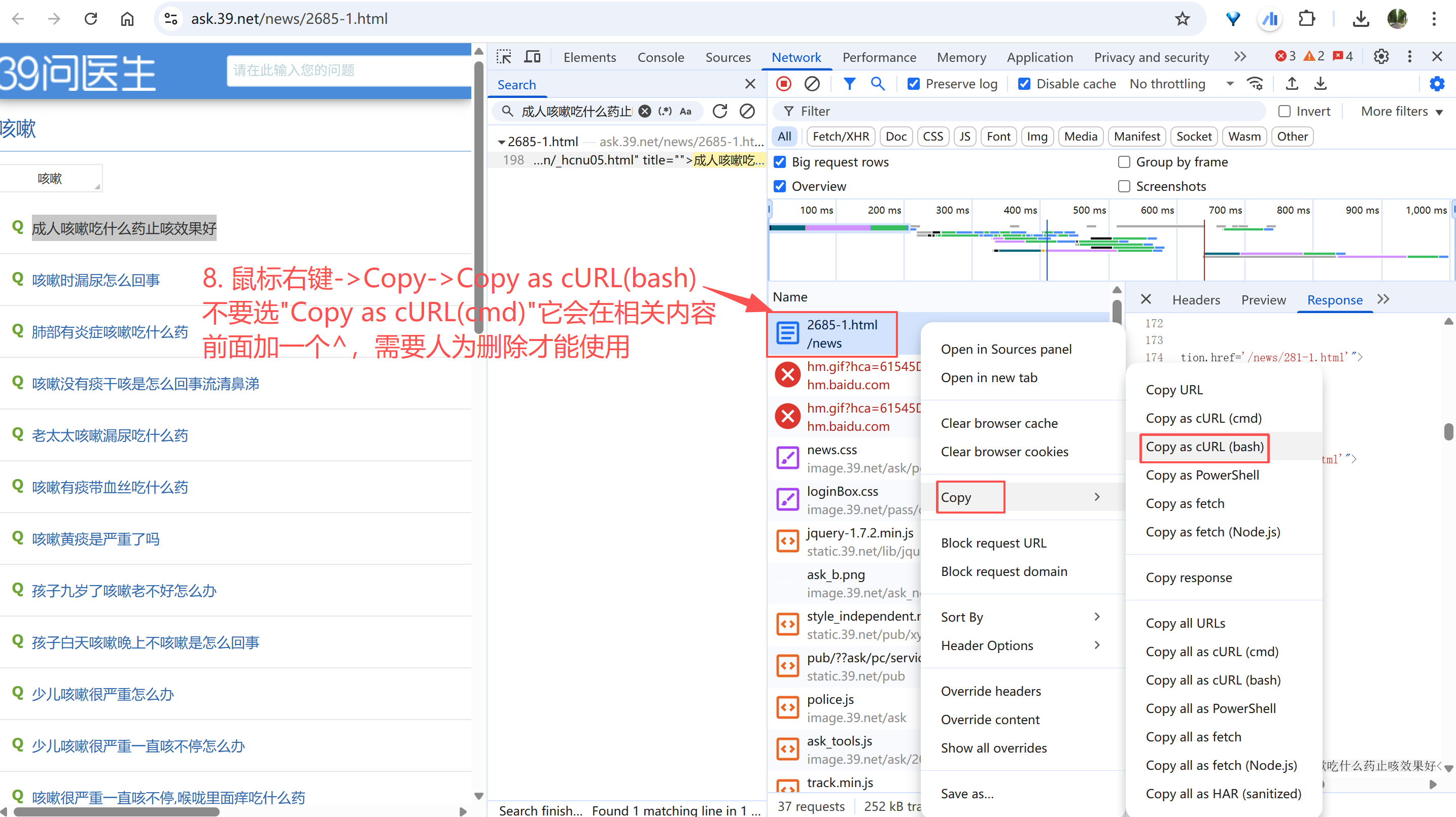
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
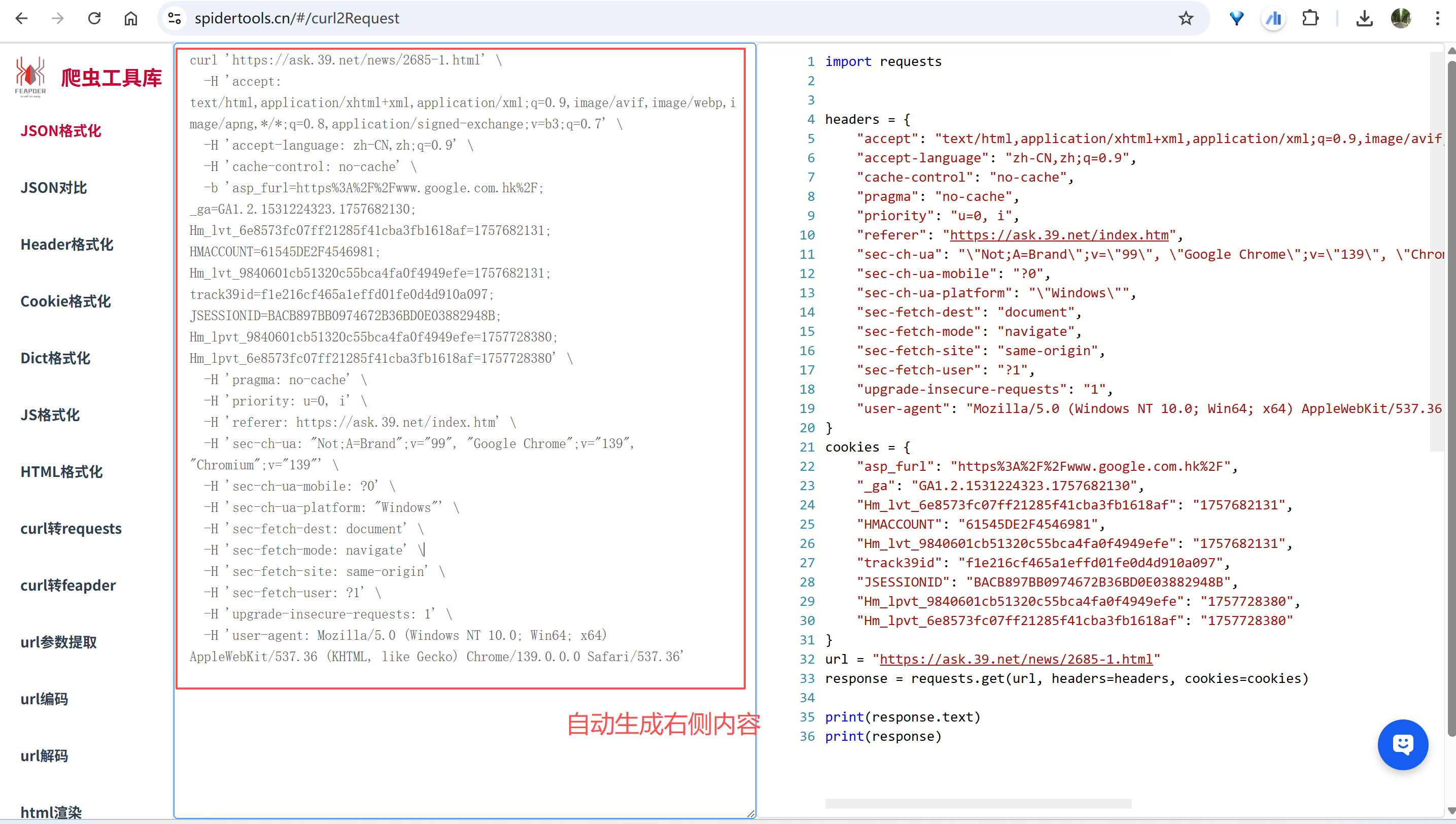
| import requests
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=0, i",
"referer": "https://ask.39.net/index.htm",
"sec-ch-ua": "\"Not;A=Brand\";v=\"99\", \"Google Chrome\";v=\"139\", \"Chromium\";v=\"139\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "same-origin",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36"
}
cookies = {
"asp_furl": "https%3A%2F%2Fwww.google.com.hk%2F",
"_ga": "GA1.2.1531224323.1757682130",
"Hm_lvt_6e8573fc07ff21285f41cba3fb1618af": "1757682131",
"HMACCOUNT": "61545DE2F4546981",
"Hm_lvt_9840601cb51320c55bca4fa0f4949efe": "1757682131",
"track39id": "f1e216cf465a1effd01fe0d4d910a097",
"JSESSIONID": "BACB897BB0974672B36BD0E03882948B",
"Hm_lpvt_9840601cb51320c55bca4fa0f4949efe": "1757728380",
"Hm_lpvt_6e8573fc07ff21285f41cba3fb1618af": "1757728380"
}
url = "https://ask.39.net/news/2685-1.html"
response = requests.get(url, headers=headers, cookies=cookies)
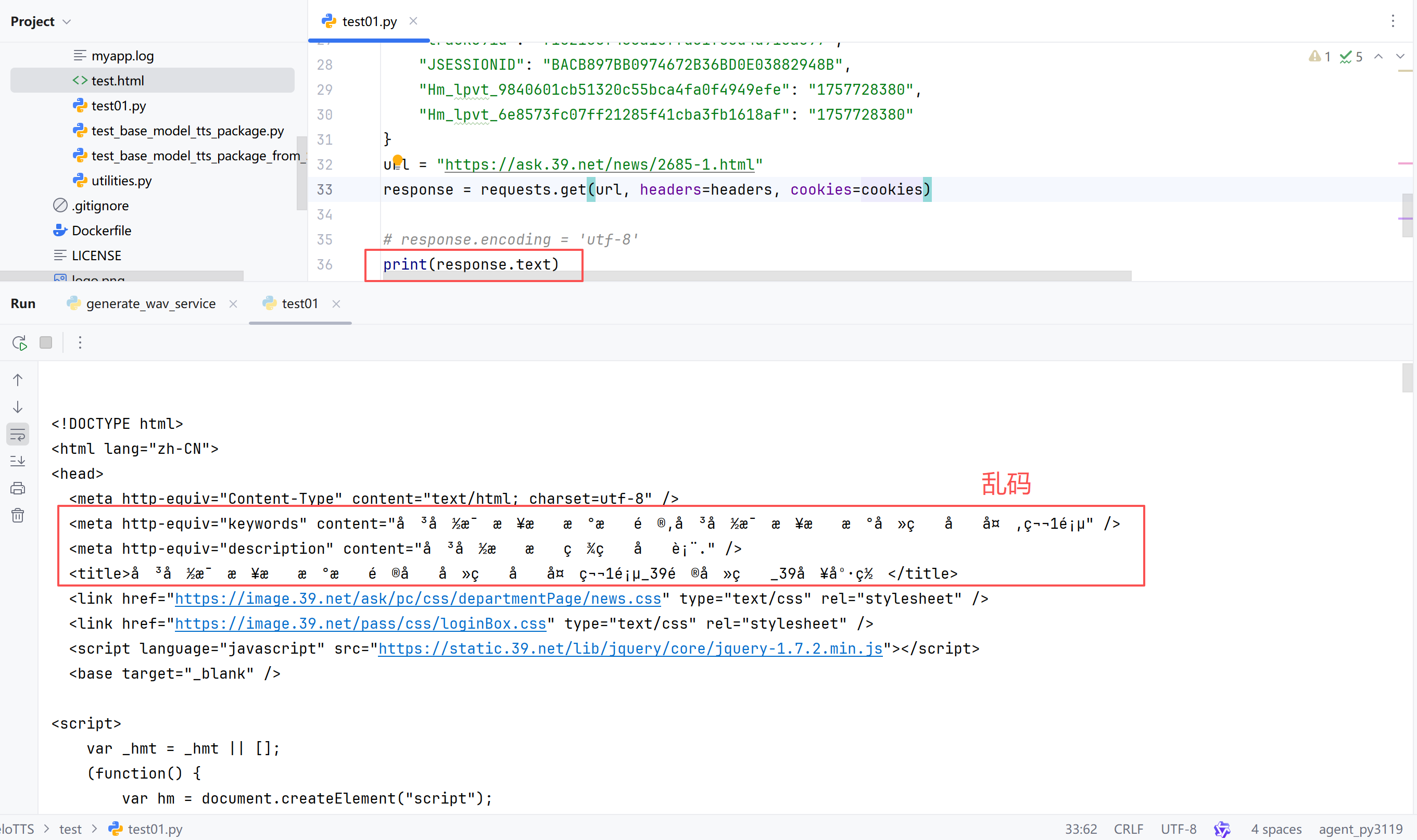
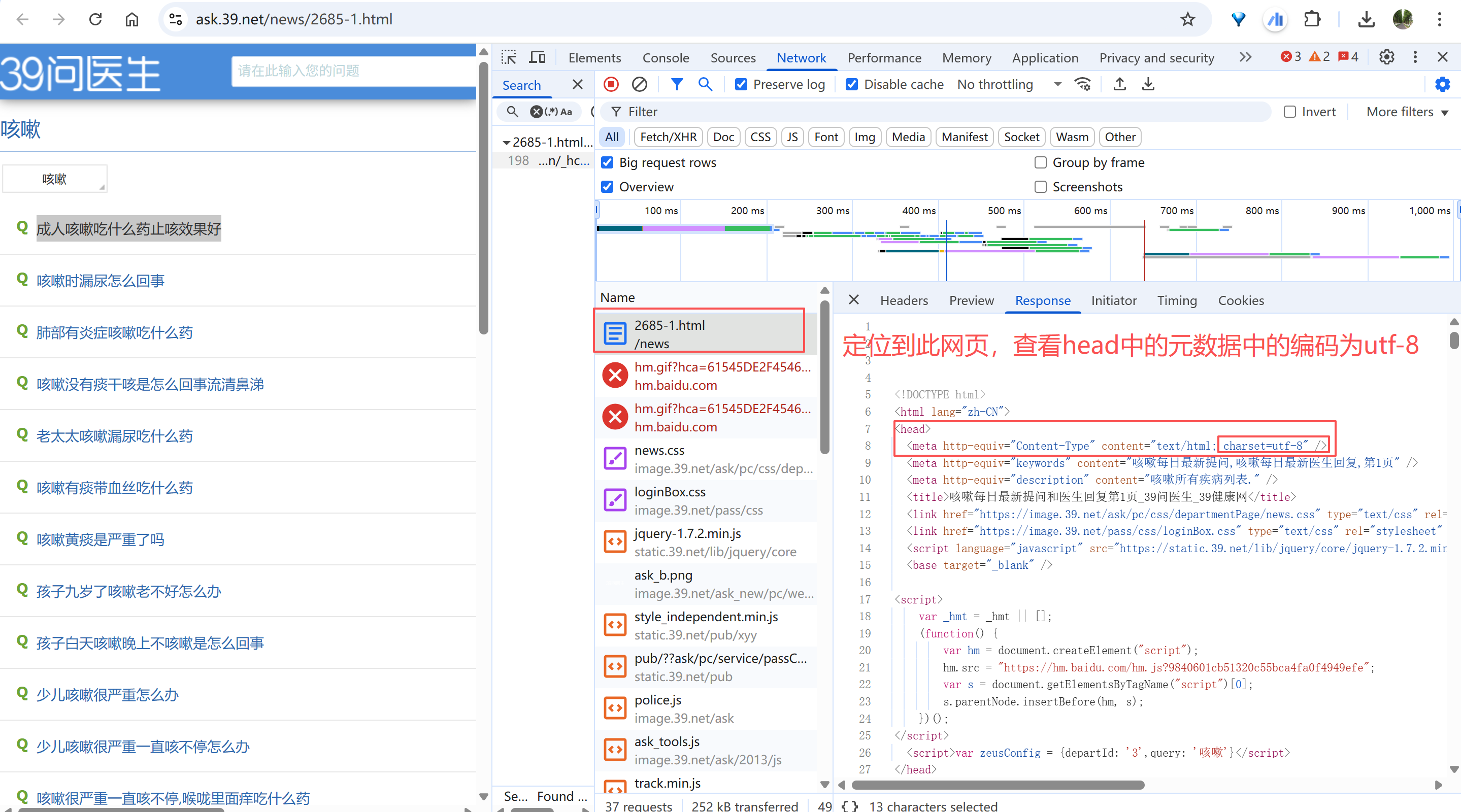
response.encoding = 'utf-8'
print(response.text)
print(response)
with open("test.html", "w", encoding="utf-8") as f:
f.write(response.text)
|